For PITCHf/x data, the starting point for pitches, in terms of the location, velocity, and acceleration, is set at 50 feet from the back of home plate. This is effectively the time-zero location of each pitch. However, 55 feet seems to be the consensus for setting an actual release point distance from home plate, and is used for all pitchers. While this is a reasonable estimate to handle the PITCHf/x data en masse, it would be interesting to see if we can calculate this on the level of individual pitchers, since their release point distances will probably vary based on a number of parameters (height, stride, throwing motion, etc.). The goal here is to try to use PITCHf/x data to estimate the average distance from home plate the each pitcher releases his pitches, conceding that each pitch is going to be released from a slightly different distance. Since we are operating in the blind, we have to first define what it means to find a pitcher’s release point distance based solely on PITCHf/x data. This definition will set the course by which we will go about calculating the release point distance mathematically.
We will define the release point distance as the y-location (the direction from home plate to the pitching mound) at which the pitches from a specific pitcher are “closest together”. This definition makes sense as we would expect the point of origin to be the location where the pitches are closer together than any future point in their trajectory. It also gives us a way to look for this point: treat the pitch locations at a specified distance as a cluster and find the distance at which they are closest. In order to do this, we will make a few assumptions. First, we will assume that the pitches near the release point are from a single bivariate normal (or two-dimensional Gaussian) distribution, from which we can compute a sample mean and covariance. This assumption seems reasonable for most pitchers, but for others we will have to do a little more work.
Next we need to define a metric for measuring this idea of closeness. The previous assumption gives us a possible way to do this: compute the ellipse, based on the data at a fixed distance from home plate, that accounts for two standard deviations in each direction along the principal axes for the cluster. This is a way to provide a two-dimensional figure which encloses most of the data, of which we can calculate an associated area. The one-dimensional analogue to this is finding the distance between two standard deviations of a univariate normal distribution. Such a calculation in two dimensions amounts to finding the sample covariance, which, for this problem, will be a 2×2 matrix, finding its eigenvalues and eigenvectors, and using this to find the area of the ellipse. Here, each eigenvector defines a principal axis and its corresponding eigenvalue the variance along that axis (taking the square root of each eigenvalue gives the standard deviation along that axis). The formula for the area of an ellipse is Area = pi*a*b, where a is half of the length of the major axis and b half of the length of the minor axis. The area of the ellipse we are interested in is four times pi times the square root of each eigenvalue. Note that since we want to find the distance corresponding to the minimum area, the choice of two standard deviations, in lieu of one or three, is irrelevant since this plays the role of a scale factor and will not affect the location of the minimum, only the value of the functional.
With this definition of closeness in order, we can now set up the algorithm. To be safe, we will take a large berth around y=55 to calculate the ellipses. Based on trial and error, y=45 to y=65 seems more than sufficient. Starting at one end, say y=45, we use the PITCHf/x location, velocity, and acceleration data to calculate the x (horizontal) and z (vertical) position of each pitch at 45 feet. We can then compute the sample covariance and then the area of the ellipse. Working in increments, say one inch, we can work toward y=65. This will produce a discrete function with a minimum value. We can then find where the minimum occurs (choosing the smallest value in a finite set) and thus the estimate of the release point distance for the pitcher.
Earlier we assumed that the data at a fixed y-location was from a bivariate normal distribution. While this is a reasonable assumption, one can still run into difficulties with noisy/inaccurate data or multiple clusters. This can be for myriad reasons: in-season change in pitching mechanics, change in location on the pitching rubber, etc. Since data sets with these factors present will still produce results via the outlined algorithm despite violating our assumptions, the results may be spurious. To handle this, we will fit the data to a Gaussian mixture model via an incremental k-means algorithm at 55 feet. This will approximate the distribution of the data with a probability density function (pdf) that is the sum of k bivariate normal distributions, referred to as components, weighted by their contribution to the pdf, where the weights sum to unity. The number of components, k, is determined by the algorithm based on the distribution of the data.
With the mixture model in hand, we then are faced with how to assign each data point to a cluster. This is not so much a problem as a choice and there are a few reasonable ways to do it. In the process of determining the pdf, each data point is assigned a conditional probability that it belongs to each component. Based on these probabilities, we can assign each data point to a component, thus forming clusters (from here on, we will use the term “cluster” generically to refer to the number of components in the pdf as well as the groupings of data to simplify the terminology). The easiest way to assign the data would be to associate each point with the cluster that it has the highest probability of belonging to. We could then take the largest cluster and perform the analysis on it. However, this becomes troublesome for cases like overlapping clusters.
A better assumption would be that there is one dominant cluster and to treat the rest as “noise”. Then we would keep only the points that have at least a fixed probability or better of belonging to the dominant cluster, say five percent. This will throw away less data and fits better with the previous assumption of a single bivariate normal cluster. Both of these methods will also handle the problem of having disjoint clusters by choosing only the one with the most data. In demonstrating the algorithm, we will try these two methods for sorting the data as well as including all data, bivariate normal or not. We will also explore a temporal sorting of the data, as this may do a better job than spatial clustering and is much cheaper to perform.
To demonstrate this algorithm, we will choose three pitchers with unique data sets from the 2012 season and see how it performs on them: Clayton Kershaw, Lance Lynn, and Cole Hamels.
Case 1: Clayton Kershaw
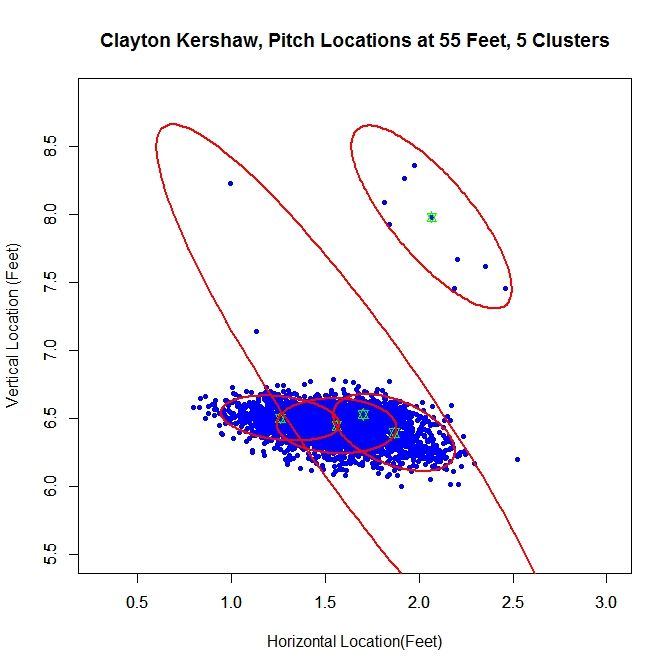
At 55 feet, the Gaussian mixture model identifies five clusters for Kershaw’s data. The green stars represent the center of each cluster and the red ellipses indicate two standard deviations from center along the principal axes. The largest cluster in this group has a weight of .64, meaning it accounts for 64% of the mixture model’s distribution. This is the cluster around the point (1.56,6.44). We will work off of this cluster and remove the data that has a low probability of coming from it. This is will include dispensing with the sparse cluster to the upper-right and some data on the periphery of the main cluster. We can see how Kershaw’s clusters are generated by taking a rolling average of his pitch locations at 55 feet (the standard distance used for release points) over the course of 300 pitches (about three starts).
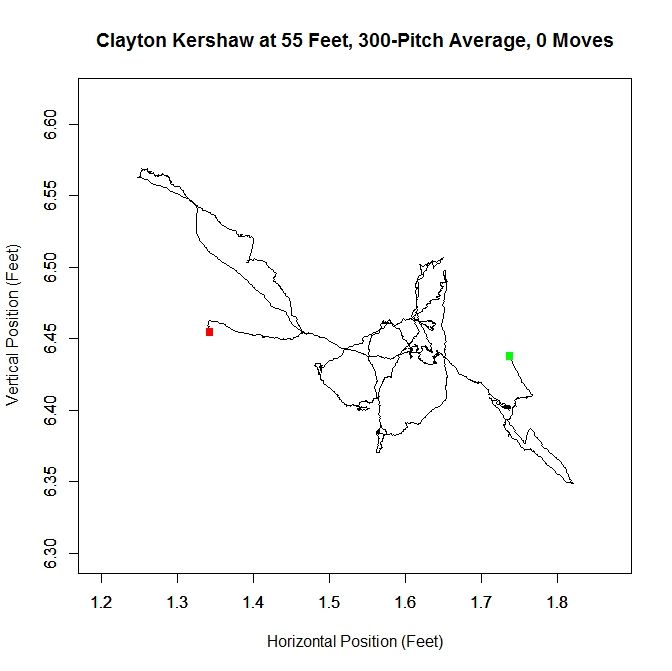
The green square indicates the average of the first 300 pitches and the red the last 300. From the plot, we can see that Kershaw’s data at 55 feet has very little variation in the vertical direction but, over the course of the season, drifts about 0.4 feet with a large part of the rolling average living between 1.5 and 1.6 feet (measured from the center of home plate). For future reference, we will define a “move” of release point as a 9-inch change in consecutive, disjoint 300-pitch averages (this is the “0 Moves” that shows up in the title of the plot and would have been denoted by a blue square in the plot). The choices of 300 pitches and 9 inches for a move was chosen to provide a large enough sample and enough distance for the clusters to be noticeably disjoint, but one could choose, for example, 100 pitches and 6 inches or any other reasonable values. So, we can conclude that Kershaw never made a significant change in his release point during 2012 and therefore treating the data a single cluster is justifiable.
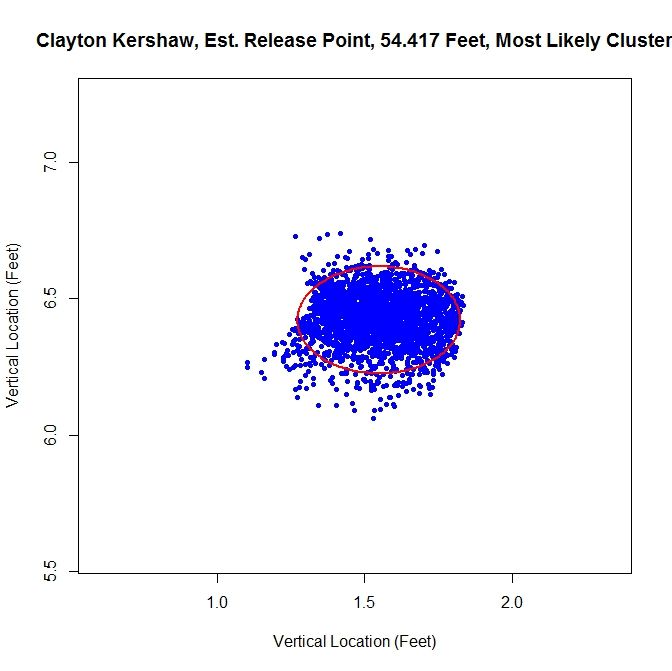
From the spatial clustering results, the first way we will clean up the data set is to take only the data which is most likely from the dominant cluster (based on the conditional probabilities from the clustering algorithm). We can then take this data and approximate the release point distance via the previously discussed algorithm. The release point for this set is estimated at 54 feet, 5 inches. We can also estimate the arm release angle, the angle a pitcher’s arm would make with a horizontal line when viewed from the catcher’s perspective (0 degrees would be a sidearm delivery and would increase as the arm was raised, up to 90 degrees). This can be accomplished by taking the angle of the eigenvector, from horizontal, which corresponds to the smaller variance. This is working under the assumption that a pitcher’s release point will vary more perpendicular to the arm than parallel to the arm. In this case, the arm angle is estimated at 90 degrees. This is likely because we have blunted the edges of the cluster too much, making it closer to circular than the original data. This is because we have the clusters to the left and right of the dominant cluster which are not contributing data. It is obvious that this way of sorting the data has the problem of creating sharp transitions at the edge of cluster.
As discussed above, we run the algorithm from 45 to 65 feet, in one-inch increments, and find the location corresponding to the smallest ellipse. We can look at the functional that tracks the area of the ellipses at different distances in the aforementioned case.
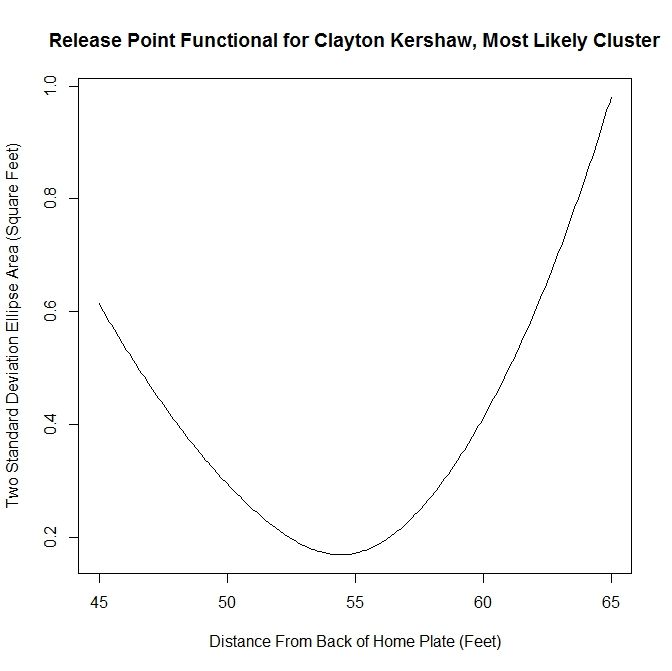
This area method produces a functional (in our case, it has been discretized to each inch) that can be minimized easily. It is clear from the plot that the minimum occurs at slightly less than 55 feet. Since all of the plots for the functional essentially look parabolic, we will forgo any future plots of this nature.
The next method is to assume that the data is all from one cluster and remove any data points that have a lower than five-percent probability of coming from the dominant cluster. This produces slightly better visual results.
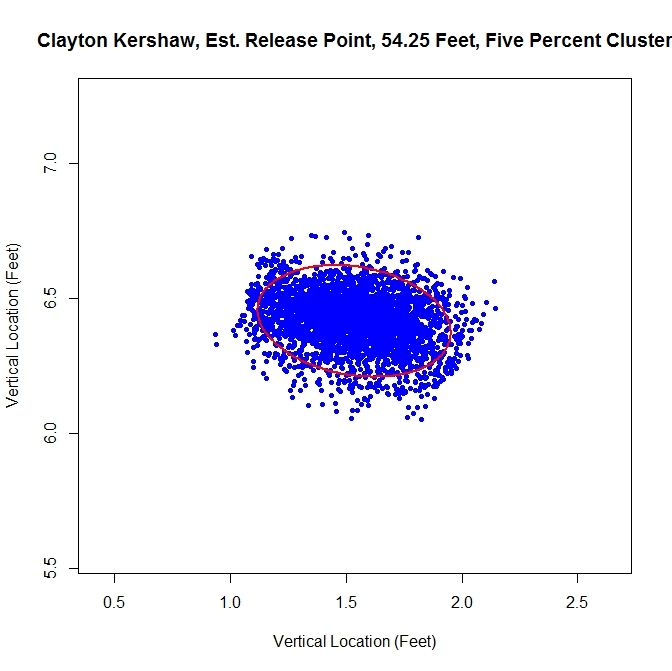
For this choice, we get trimming away at the edges, but it is not as extreme as in the previous case. The release point is at 54 feet, 3 inches, which is very close to our previous estimate. The arm angle is more realistic, since we maintain the elliptical shape of the data, at 82 degrees.
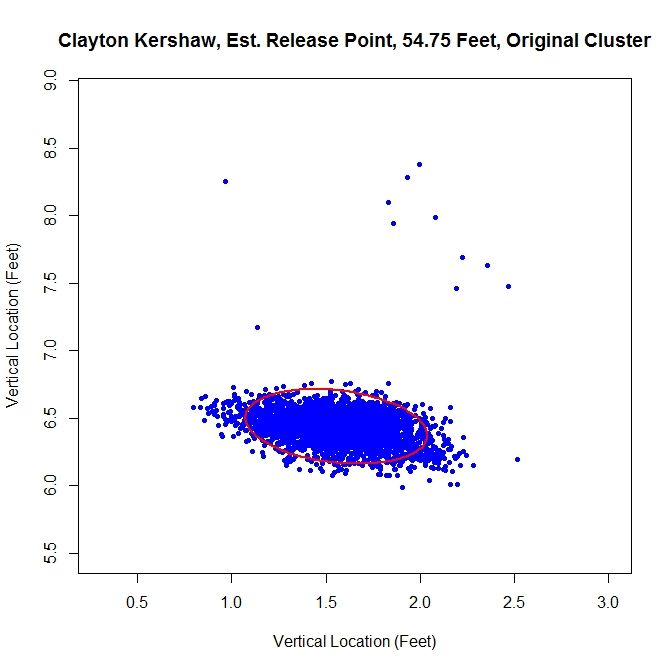
Finally, we will run the algorithm with the data as-is. We get an ellipse that fits the original data well and indicates a release point of 54 feet, 9 inches. The arm angle, for the original data set, is 79 degrees.
Examining the results, the original data set may be the one of choice for running the algorithm. The shape of the data is already elliptic and, for all intents and purposes, one cluster. However, one may still want to remove manually the handful of outliers before preforming the estimation.
Case 2: Lance Lynn
Clayton Kershaw’s data set is much cleaner than most, consisting of a single cluster and a few outliers. Lance Lynn’s data has a different structure.
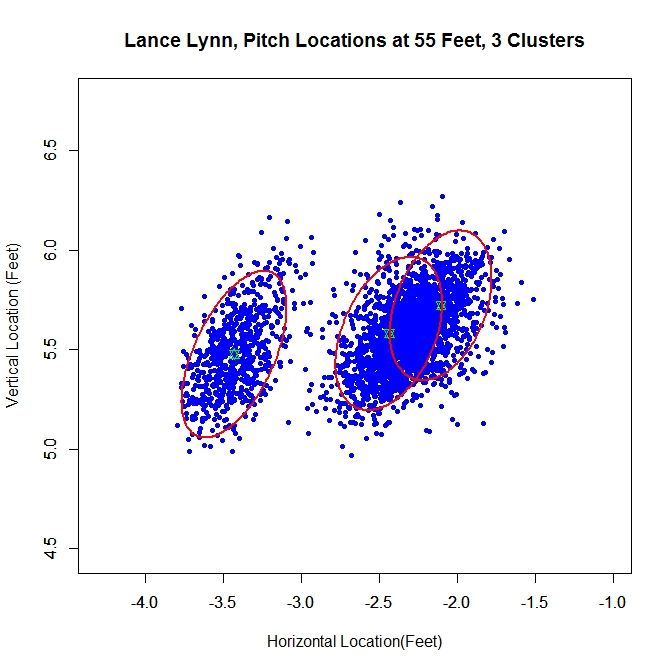
The algorithm produces three clusters, two of which share some overlap and the third disjoint from the others. Immediately, it is obvious that running the algorithm on the original data will not produce good results because we do not have a single cluster like with Kershaw. One of our other choices will likely do better. Looking at the rolling average of release points, we can get an idea of what is going on with the data set.
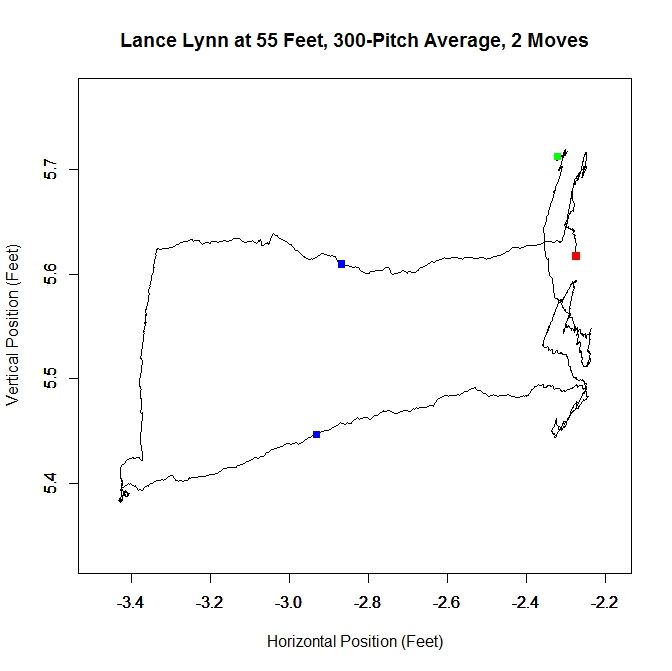
From the rolling average, we see that Lynn’s release point started around -2.3 feet, jumped to -3.4 feet and moved back to -2.3 feet. The moves discussed in the Kershaw section of 9 inches over consecutive, disjoint 300-pitch sequences are indicated by the two blue squares. So around Pitch #1518, Lynn moved about a foot to the left (from the catcher’s perspective) and later moved back, around Pitch #2239. So it makes sense that Lynn might have three clusters since there were two moves. However his first and third clusters could be considered the same since they are very similar in spatial location.
Lynn’s dominant cluster is the middle one, accounting for about 48% of the distribution. Running any sort of analysis on this will likely draw data from the right cluster as well. First up is the most-likely method:
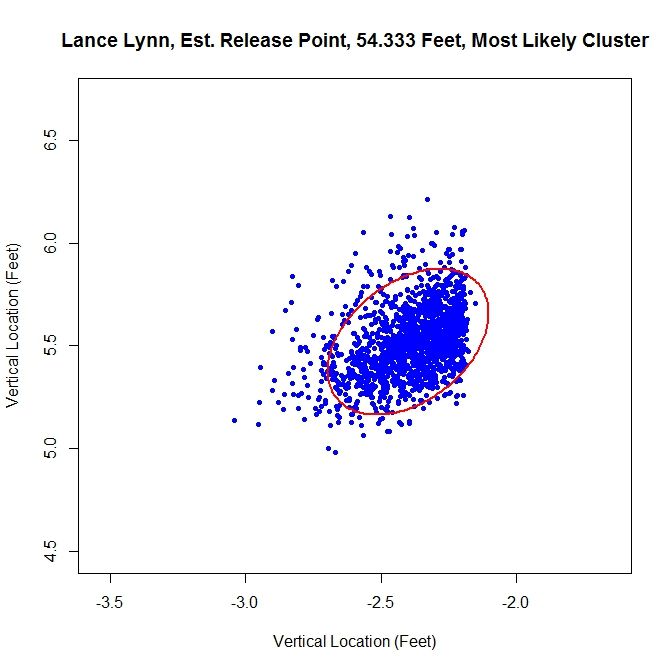
Since we have two clusters that overlap, this method sharply cuts the data on the right hand side. The release point is at 54 feet, 4 inches and the release angle is 33 degrees. For the five-percent method, the cluster will be better shaped since the transition between clusters will not be so sharp.
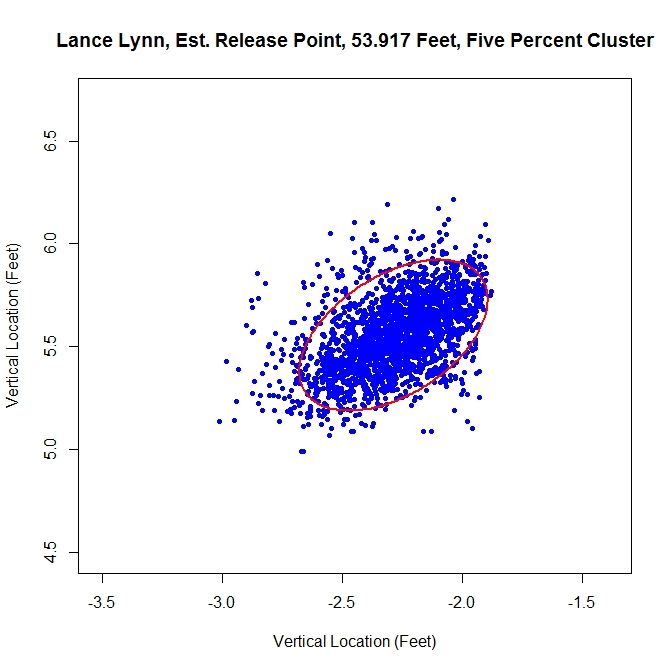
This produces a well-shaped single cluster which is free of all of the data on the left and some of the data from the far right cluster. The release point is at 53 feet, 11 inches and at an angle of 49 degrees.
As opposed to Kershaw, who had a single cluster, Lynn has at least two clusters. Therefore, running this method on the original data set probably will not fare well.
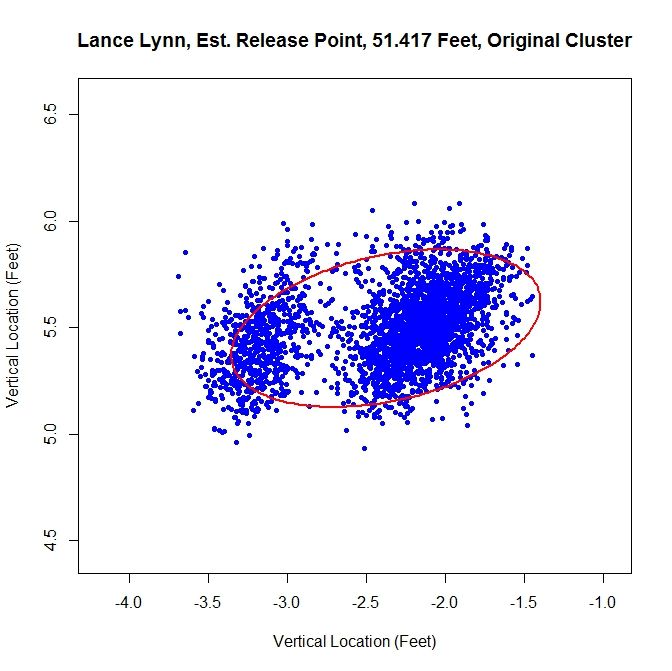
Having more than one cluster and analyzing it as only one causes both a problem with the release point and release angle. Since the data has disjoint clusters, it violates our bivariate normal assumption. Also, the angle will likely be incorrect since the ellipse will not properly fit the data (in this instance, it is 82 degrees). Note that the release point distance is not in line with the estimates from the other two methods, being 51 feet, 5 inches instead of around 54 feet.
In this case, as opposed to Kershaw, who only had one pitch cluster, we can temporally sort the data based on the rolling average at the blue square (where the largest difference between the consecutive rolling averages is located).
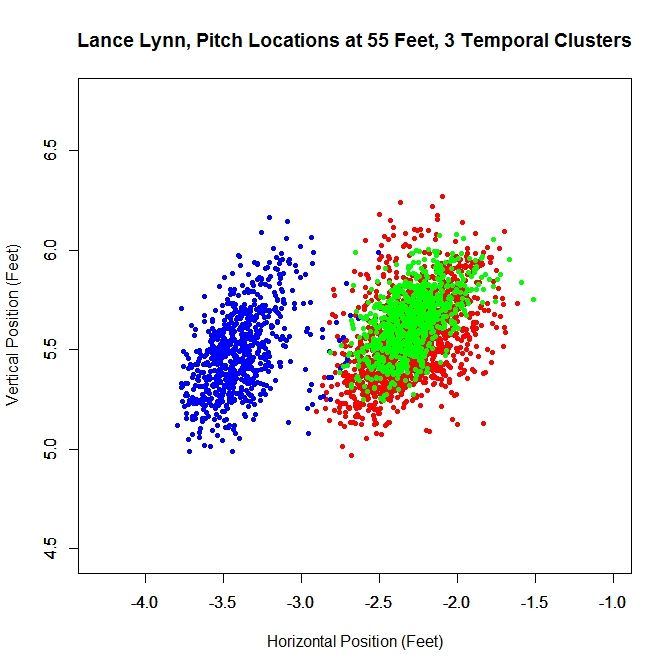
Since there are two moves in release point, this generates three clusters, two of which overlap, as expected from the analysis of the rolling averages. As before, we can work with the dominant cluster, which is the red data. We will refer to this as the largest method, since it is the largest in terms of number of data points. Note that with spatial clustering, we would pick up the some of the green and red data in the dominant cluster. Running the same algorithm for finding the release point distance and angle, we get:
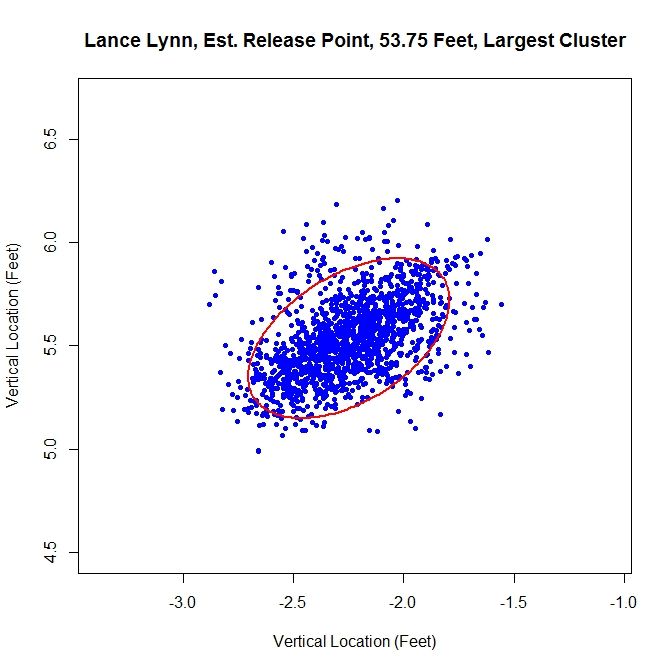
The distance from home plate of 53 feet, 9 inches matches our other estimates of about 54 feet. The angle in this case is 55 degrees, which is also in agreement. To finish our case study, we will look at another data set that has more than one cluster.
Case 3: Cole Hamels
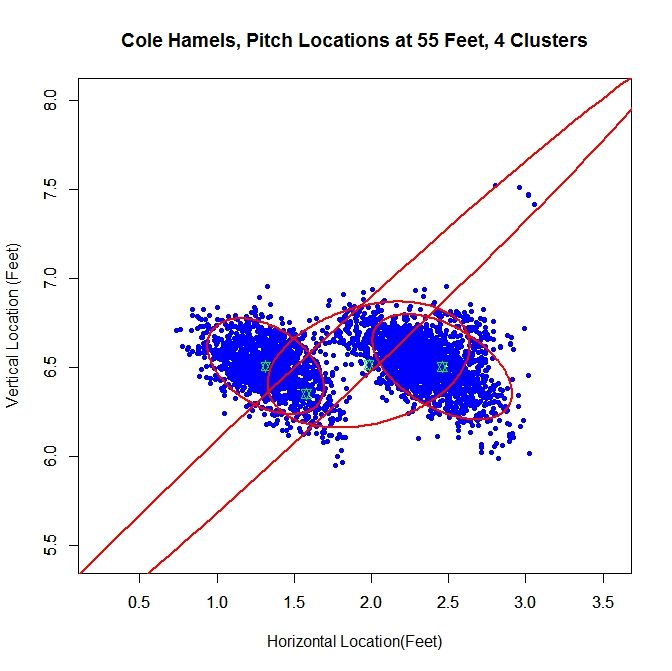
For Cole Hamels, we get two dense clusters and two sparse clusters. The two dense clusters appear to have a similar shape and one is shifted a little over a foot away from the other. The middle of the three consecutive clusters only accounts for 14% of the distribution and the long cluster running diagonally through the graph is mostly picking up the handful of outliers, and consists of less than 1% of the distribution. We will work with the the cluster with the largest weight, about 0.48, which is the cluster on the far right. If we look at the rolling average for Hamels’ release point, we can see that he switched his release point somewhere around Pitch #1359 last season.
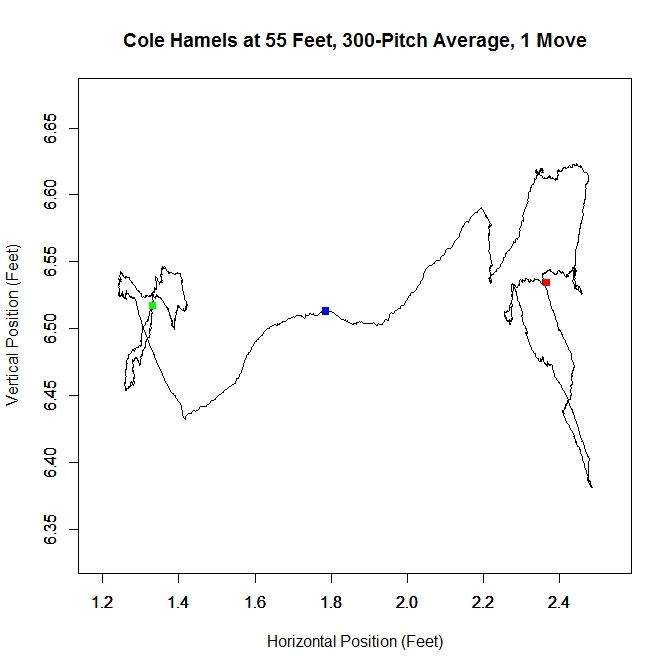
As in the clustered data, Hamel’s release point moves horizontally by just over a foot to the right during the season. As before, we will start by taking only the data which most likely belongs to the cluster on the right.
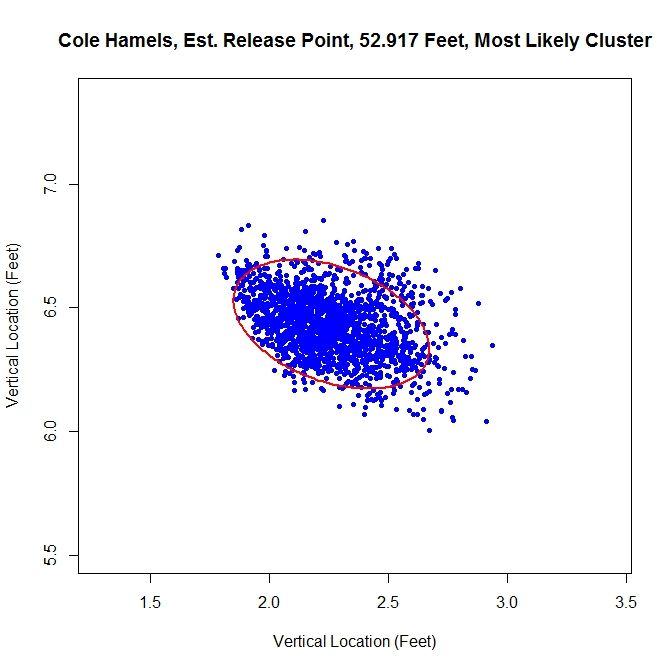
The release point distance is estimated at 52 feet, 11 inches using this method. In this case, the release angle is approximately 71 degrees. Note that on the top and the left the data has been noticeably trimmed away due to assigning data to the most likely cluster. The five-percent method produces:
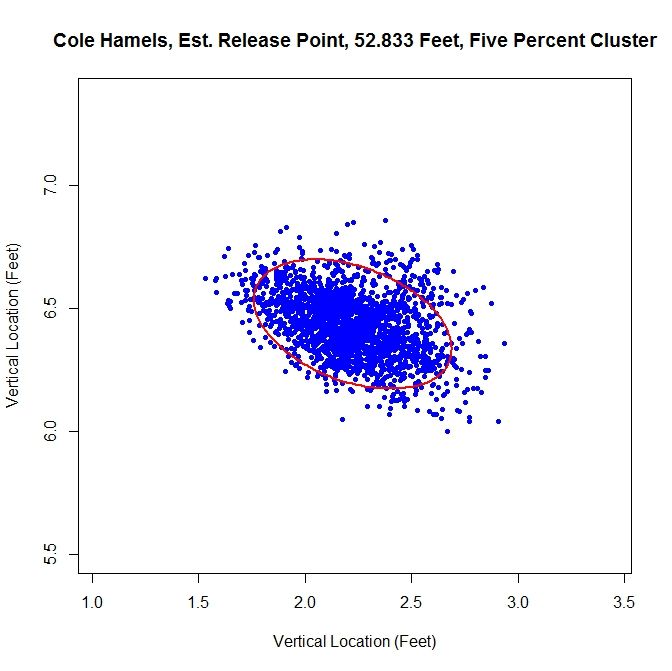
For this method of sorting through the data, we get 52 feet, 10 inches for the release point distance. The cluster has a better shape than the most-likely method and gives a release angle of 74 degrees. So far, both estimates are very close. Using just the original data set, we expect that the method will not perform well because there are two disjoint clusters.
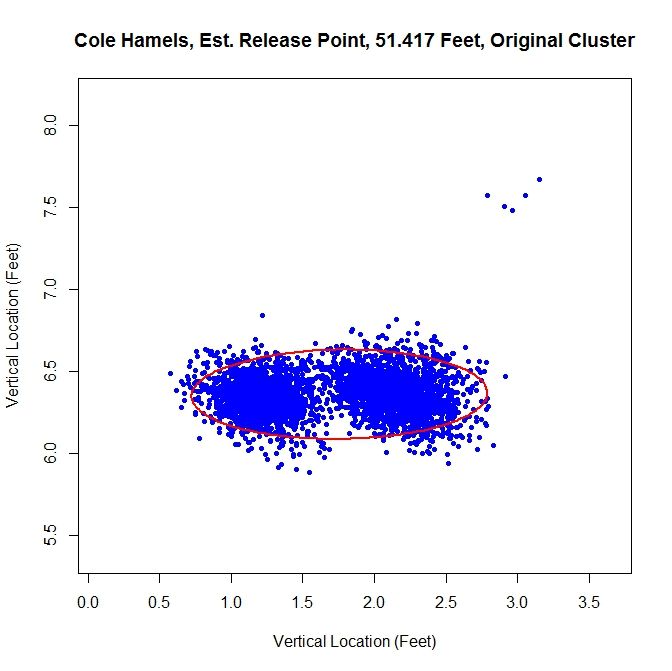
We run into the problem of treating two clusters as one and the angle of release goes to 89 degrees since both clusters are at about the same vertical level and therefore there is a large variation in the data horizontally.
Just like with Lance Lynn, we can do a temporal splitting of the data. In this case, we get two clusters since he changed his release point once.
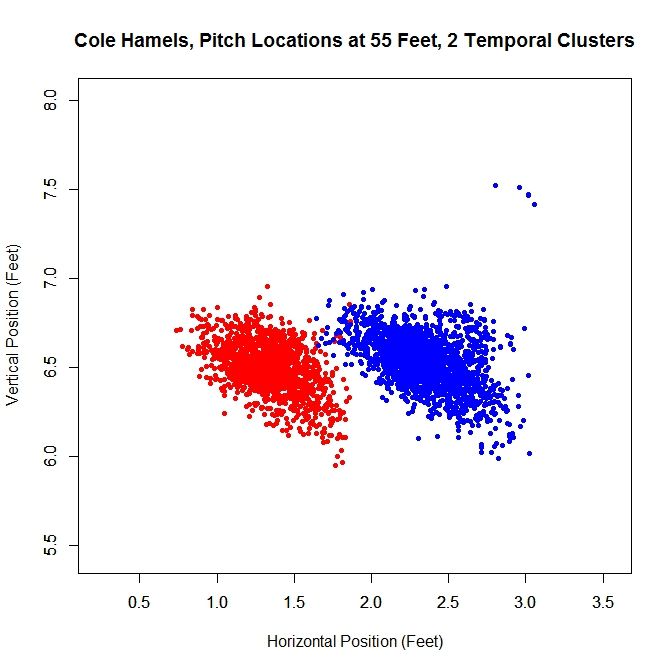
Working with the dominant cluster, the blue data, we obtain a release point at 53 feet, 2 inches and a release angle of 75 degrees.
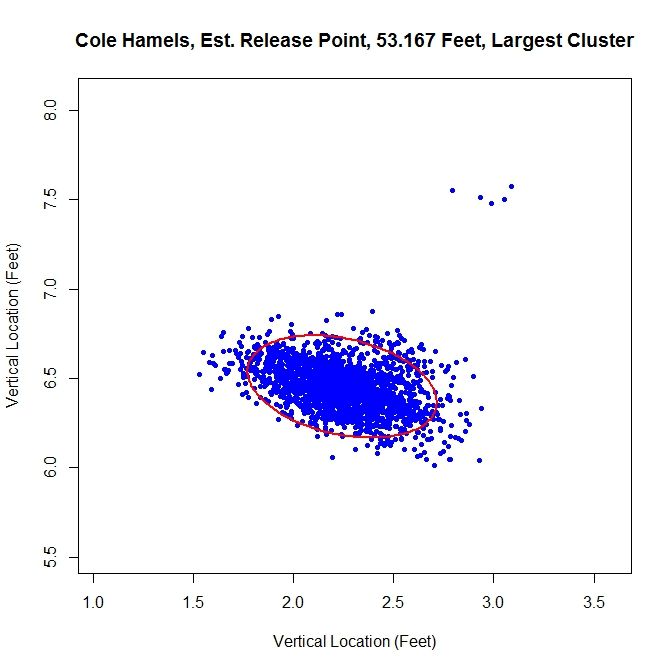
All three methods that sort the data before performing the algorithm lead to similar results.
Conclusions:
Examining the results of these three cases, we can draw a few conclusions. First, regardless of the accuracy of the method, it does produce results within the realm of possibility. We do not get release point distances that are at the boundary of our search space of 45 to 65 feet, or something that would definitely be incorrect, such as 60 feet. So while these release point distances have some error in them, this algorithm can likely be refined to be more accurate. Another interesting result is that, provided that the data is predominantly one cluster, the results do not change dramatically due to how we remove outliers or smaller additional clusters. In most cases, the change is typically only a few inches. For the release angles, the five-percent method or largest method probably produces the best results because it does not misshape the clusters like the mostly-likely method does and does not run into the problem of multiple clusters that may plague the original data. Overall, the five-percent method is probably the best bet for running the algorithm and getting decent results for cases of repeated clusters (Lance Lynn) and the largest method will work best for disjoint clusters (Cole Hamels). If just one cluster exists, then working with the original data would seem preferable (Clayton Kershaw).
Moving forward, the goal is settle on a single method for sorting the data before running the algorithm. The largest method seems the best choice for a robust algorithm since it is inexpensive and, based on limited results, performs on par with the best spatial clustering methods. One problem that comes up in running the simulations that does not show up in the data is the cost of the clustering algorithm. Since the method for finding the clusters is incremental, it can be slow, depending on the number of clusters. One must also iterate to find the covariance matrices and weights for each cluster, which can also be expensive. In addition, the spatial clustering only has the advantages of removing outliers and maintaining repeated clusters, as in Lance Lynn’s case. Given the difference in run time, a few seconds for temporal splitting versus a few hours for spatial clustering, it seems a small price to pay. There are also other approaches that can be taken. The data could be broken down by start and sorted that way as well, with some criteria assigned to determine when data from two starts belong to the same cluster.
Another problem exists that we may not be able to account for. Since the data for the path of a pitch starts at 50 feet and is for tracking the pitch toward home plate, we are essentially extrapolating to get the position of the pitch before (for larger values than) 50 feet. While this may hold for a small distance, we do not know exactly how far this trajectory is correct. The location of the pitch prior to its individual release point, which we may not know, is essentially hypothetical data since the pitch never existed at that distance from home plate. This is why is might be important to get a good estimate of a pitcher’s release point distance.
There are certainly many other ways to go about estimating release point distance, such as other ways to judge “closeness” of the pitches or sort the data. By mathematizing the problem, and depending on the implementation choices, we have a means to find a distinct release point distance. This is a first attempt at solving this problem which shows some potential. The goal now is to refine it and make it more robust.
Once the algorithm is finalized, it would be interesting to go through video and see how well the results match reality, in terms of release point distance and angle. As it is, we are essentially operating blind since we are using nothing but the PITCHf/x data and some reasonable assumptions. While this worked to produce decent results, it would be best to create a single, robust algorithm that does not require visual inspection of the data for each case. When that is completed, we could then run the algorithm on a large sample of pitchers and compare the results.

 *
* *
* *
*



















{kind=link}