Predicting Hall of Famers with Machine Learning
The questions of who should and who will make it into the Baseball Hall of Fame have inspired countless debates, books, articles, and statistics. From the early days of statistical milestones like 3,000 hits, 500 home runs, and 300 wins to more advanced measurements like WAR and JAWS, and throughout baseball’s many eras, many have attempted to tackle the task. The discussion is more or less ongoing but peaks whenever a prominent player retires and during every winter ballot season. Innovations like the Hall of Fame Tracker have only added fuel to the fire.
I wanted to see if machine learning was up to the task of predicting who’ll get enshrined. I trained and evaluated a prediction model and used it to predict induction chances for current and recently retired players. I specifically wanted to see if I could get a sense of how some of the game’s younger superstars are doing, because who doesn’t want to talk about how good Juan Soto is?
In this article I discuss building and evaluating the model and show the predictions it makes. If you’re interested in the former, continue reading; if you’re interested only in the predictions, feel free to skip to the end.
Data
Conceptually, I consider induction chance as a player’s skill at accumulating the most value as quickly as possible at a certain position, all while avoiding major scandals. Specifically, I trained the model using the following data points:
- Position: Most of the time this is the position where the player spent the most innings. Because “outfielder” isn’t a position in the Hall of Fame, I separate out everyone by their actual fielding position. This causes some weirdness, like making Cody Bellinger a first baseman because he has more innings there than at any outfield position, but it works. For Hall of Fame inductees I consulted the official Hall of Fame website and, when specific outfield positioning wasn’t available, cooperstownexpert.com. I also discarded relief pitchers. Reliever induction is all over the map and the selection of Mariano Rivera has made things less clear than ever (or perhaps more clear? I’m not clear).
- Age: the age a player was when he accrued this WAR.
- Cumulative WAR at this age: the WAR accrued through each age in the dataset. For position players, I use FanGraphs WAR. For pitchers, I use an average of their FIP-based WAR and RA9-WAR. This approach blends the modern sabermetric style of evaluating pitchers and the more traditional runs-based style.
- Mean Year: the average of a player’s debut and final years. This data point encapsulates the era a player played in. As we’ll see later, this data point plays a large role in predicting induction.
- Scandal: I defined several types of scandals and marked players accordingly:
- PEDs: your big names like Barry Bonds and Alex Rodriguez go here as well as folks like Dee Strange-Gordon and Starling Marte. I included Andy Pettitte and David Ortiz in this group. Remember Melky Cabrera’s fake website?
- Gambling: the eight members of the 1919 Chicago White Sox who were banned, along with Joe Gedeon and Pete Rose.
- Cheating: major members of the 2017 Astros go here, as well as Gaylord Perry.
- Domestic violence: Marcell Ozuna, Aroldis Chapman, Omar Vizquel, etc.
- Miscellaneous: Curt Schilling and Lenny Dykstra are in this group. These guys may not have committed any damning crimes or been punished within the game, but they’re viewed as less-than-savory characters for a variety of reasons.
I used this data to predict the chances a player will be inducted into the Hall of Fame as a player in the American or National Leagues. This means I excluded those who were elected as a manager or executive or who were elected primarily for their Negro Leagues careers.
I didn’t distinguish between getting inducted by the BBWAA or a committee. Keep this in mind when looking at the results. Some players who we think won’t get elected will be ignored by the BBWAA but will get in via committee.
Training the Model
I built a binary classifier (elected / not-elected) using xgboost, training it on season-by-season data from players who retired in 2015 or earlier and who appeared in parts of at least 10 seasons (as well as Addie Joss). This gave me 33,904 player-seasons, of which 4,114 (12.1%) belong to a player who was inducted. To account for this relatively small percentage of inductees, I use SMOTE and stratified sampling to build training and testing datasets. I tuned the hyperparameters on the training dataset by repeating 10-fold cross-validation five times.
Evaluating the Model
I evaluated the model on the testing dataset that I kept separate from the training dataset. Because of the small number of inductee seasons, I used balanced accuracy, the F1 score, and a precision-recall curve to evaluate the model’s performance. Were the classes more balanced, simple accuracy and an ROC curve would’ve sufficed.
Let’s start with a confusion matrix:
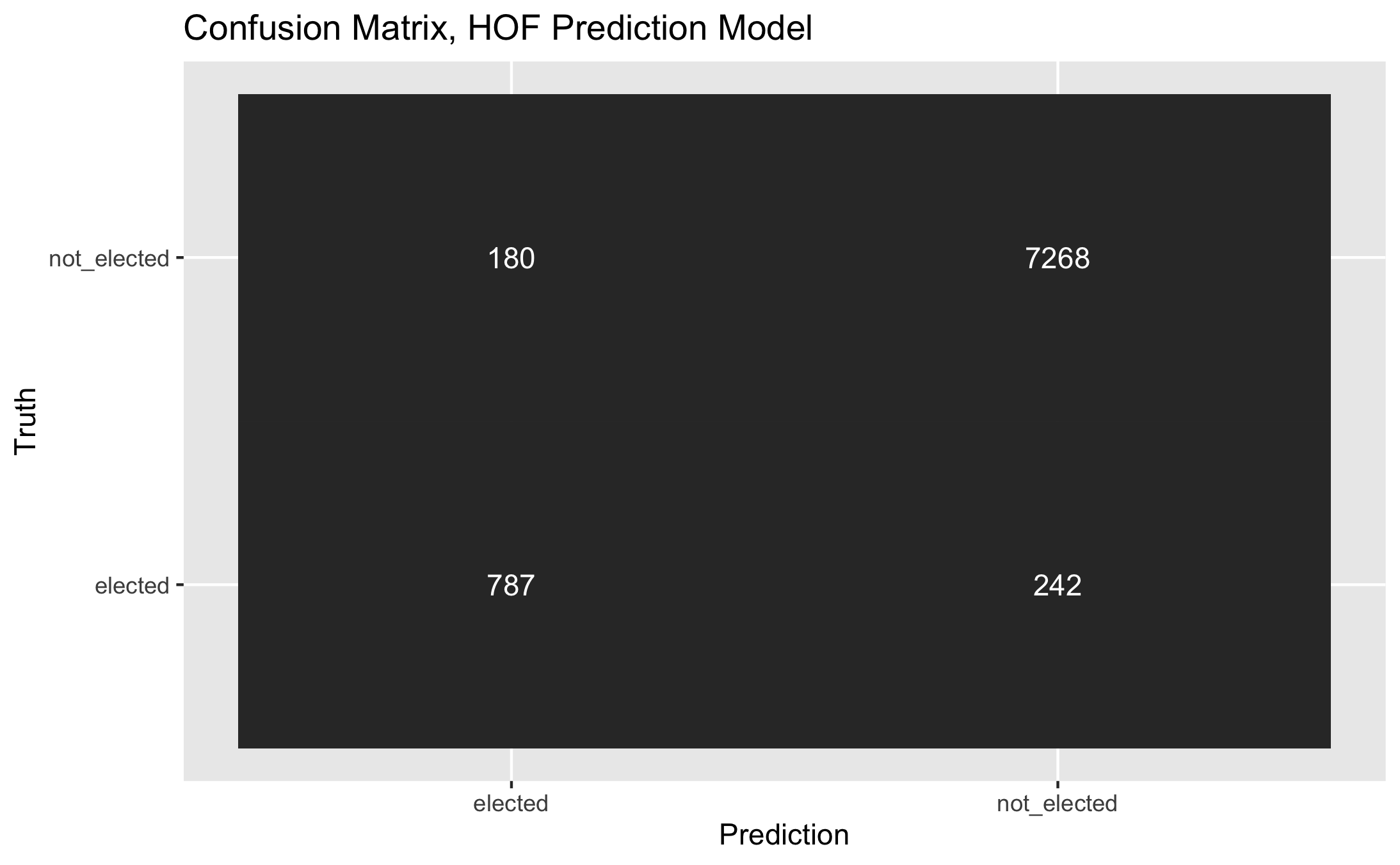
Two metrics give a quick sense of the model’s performance:
- The balanced accuracy, which averages the accuracy of correctly predicting both inductions and exclusions, is 87%.
- The F1 score, which is the harmonic mean of the model’s precision and recall, is 0.79 out of a maximum possible value of 1.
Precision measures the accuracy of the model’s predicted inductees. It asks, “of the predicted inductees, how many were actually inducted?” Recall measures the completeness of the model’s predictions. It asks, “of the actual inductees, how many did the model predict?”
Speaking of precision and recall, the last thing to look at is a precision-recall curve:

An area of of 0.87, out of a maximum of 1, indicates the model captures a lot of additional value beyond a random guess. The line at .121 denotes a random guess based on the training data — remember that 12.1% of player-seasons in the datasets resulted in an induction. The curve demonstrates how the model trades off between precision and recall as you adjust the cutoff point between predicting exclusion and induction. The area under this curve shows how much additional information the model captures as compared to a random guess.
I know I’ve thrown a lot of numbers at you, but it’s helpful to understand one more: 21.25%. Given the way the model is constructed, if it predicts someone’s induction chances at this level or higher, calling them a Hall of Famer maximizes the area underneath the curve. Remember this cutoff point when I predict induction chances for actual players below.
Taken together, the balanced accuracy, F1 score, and area under the precision-recall curve indicate the model performs well at identifying Hall of Fame-worthy seasons.
What Makes a Hall of Fame Player?
Since the model seems useful, I wanted to know which factors (of the ones I used) are most important in a player’s Hall of Fame chances. Here’s what the algorithm told me:
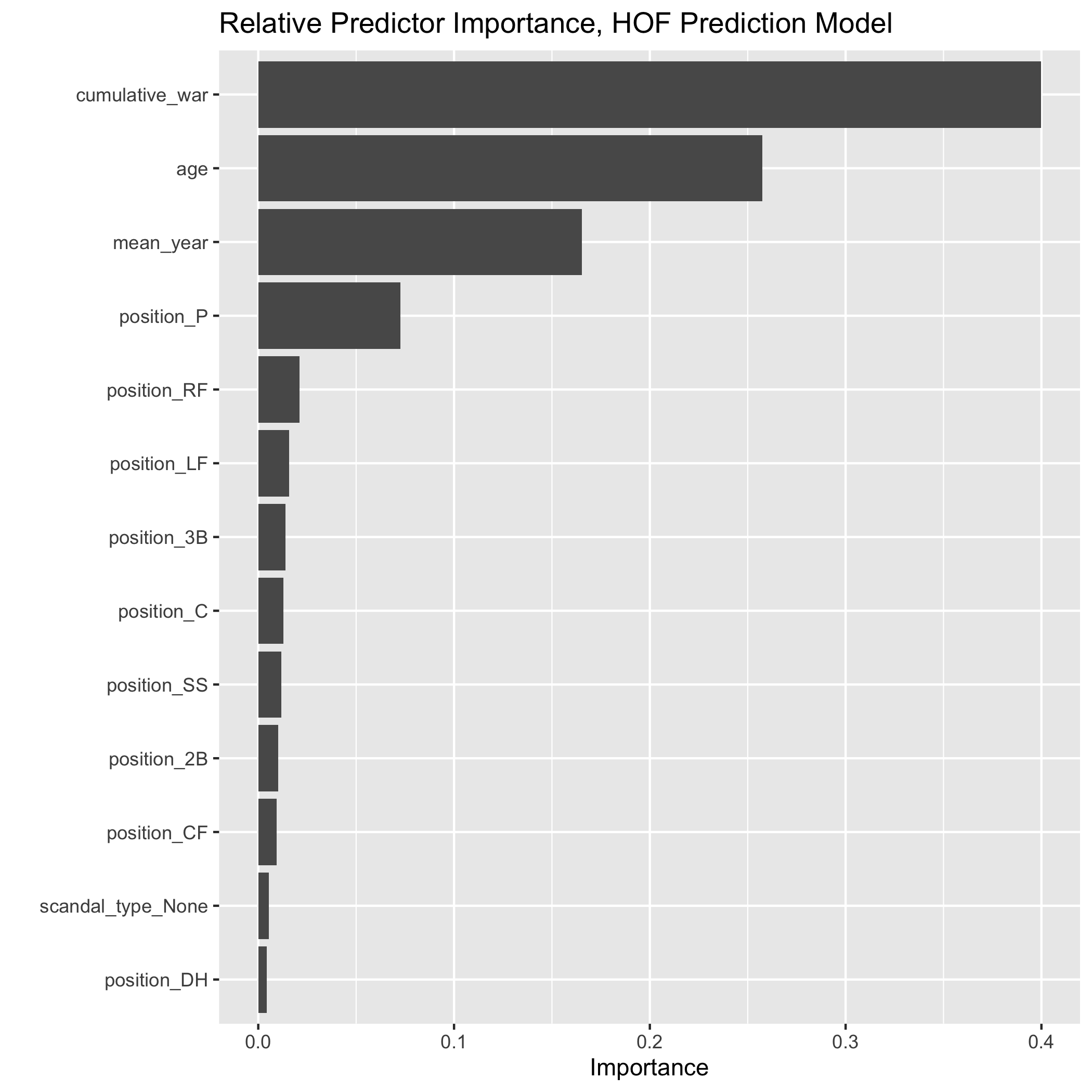
You can tell a lot about player’s induction chances by looking at how old they are and how much WAR they’ve accumulated. The third most important variable is the era during which the player played, as represented by the average of their first and last years. This variable captures the fact that Hall of Fame standards and voting patterns have changed drastically over time. Traditional standards like a certain number of hits, home runs, or (for pitchers) strikeouts are in question because of issues like PEDs, considering defensive value, and the decline in usage of starting pitchers. You also have off-field trends like who’s in the BBWAA and on the different committees, how they perceive different candidates, and who else is on the ballot.
With respect to the positions, think of each line as a true/false question: “is the player a (starting) pitcher?” “Is the player a right fielder?” and so on. Machine learning algorithms frame multiple-choice questions like “what position is a player?” in this way. It’s a bit more complicated but allows the algorithm to fully understand the information.
Here we see that the most important positional question is knowing whether a player is a pitcher. This makes sense because of the distinction between how pitchers accumulate WAR, how long their careers last, the statistics and standards by which they’re judged, and so on.
Looking towards the bottom we see that being scandal-free has a relatively minor effect on your chances of getting elected. This isn’t to say that being scandal free isn’t a concern; rather, it’s much less of a concern than the other factors here. I think the model is a bit misguided here, as the only scandal-heavy player who’s been inducted is Gaylord Perry. I think being scandal-free will become more important at Bonds, Schilling, et al. fall off the ballot.
Predicting Today’s Hall of Famers
Given the good performance of the model, I asked it to predict Hall of Famers from a population of players whom we don’t have voting results for yet. I didn’t predict anyone who is on the 2022 ballot because I used their data to train the model. Besides, it’s more fun to wish and dream on Ronald Acuña Jr. and Wander Franco than it is to re-hash the arguments for guys like Barry Bonds and Roger Clemens for the billionth time.
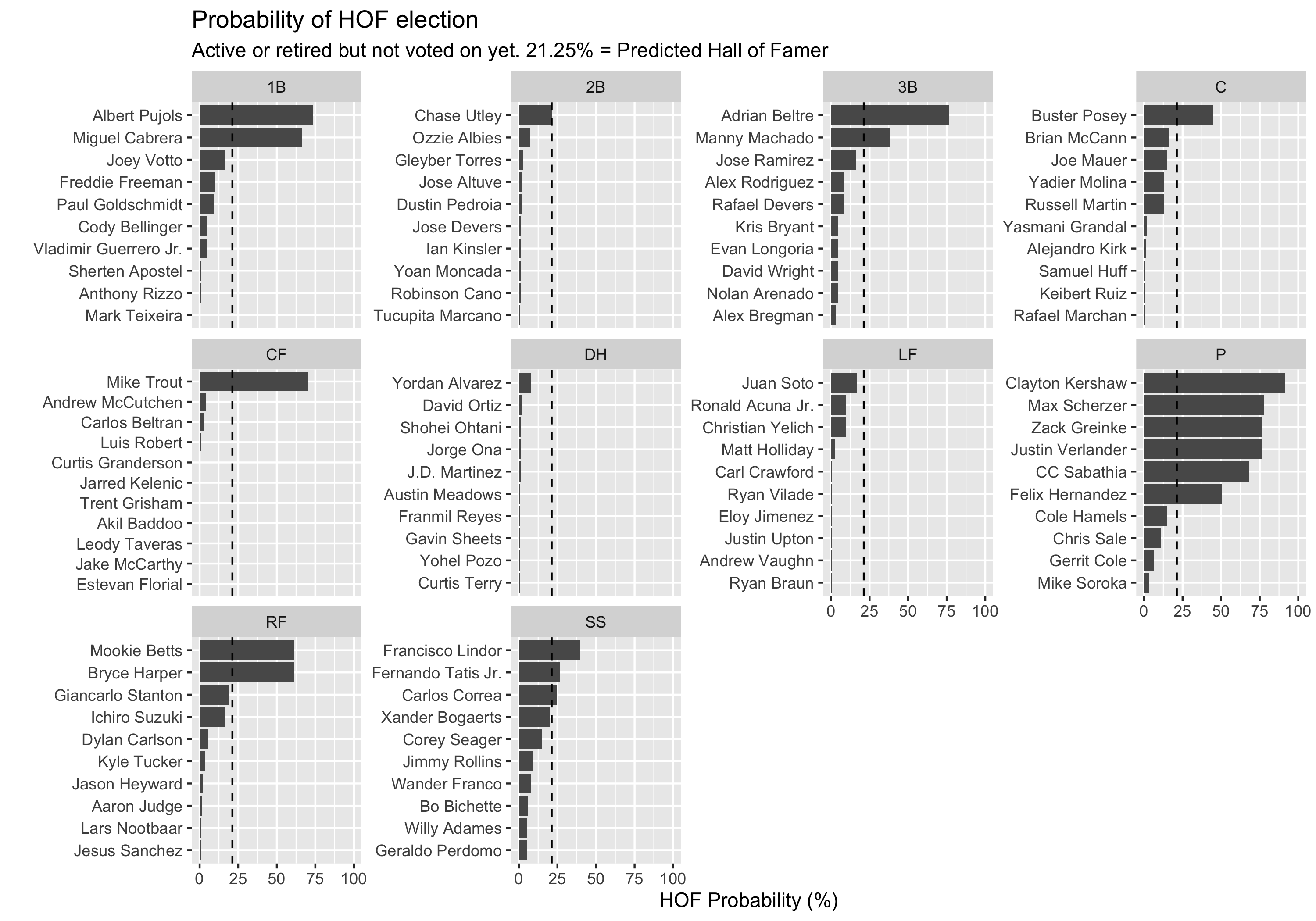
(Click image to view a larger version.)
There’s a lot to unpack here. The model nails the players who are commonly referred to as active Hall of Famers who are nearing the ends of their careers. It also identifies younger superstars like Mookie Betts and Bryce Harper who don’t get discussed as much as the older guys.
More importantly, the model highlights some names I haven’t considered. Is Giancarlo Stanton a Hall of Famer? He’s been injured so much lately, I forgot he has over 42 WAR in right field through age 31. That’s not too different from consensus guys like Betts (44 WAR through age 28).
How about Francisco Lindor? He was such a disappointment in 2021 that I forgot not only how young he is, but also that he garnered almost 3 WAR in a down year. Through his age-27 season he’s accumulated over 30 WAR. Of the 15 non-active, not-on-the-ballot shortstops who had between 30 and 35 WAR between ages 25 to 29, 11 have made the Hall.
Speaking of pitchers: what about Félix Hernández? The model is very bullish on his chances. For the purposes of this exercise, he’s accumulated 55.5 WAR through age 33. (Remember that I’m averaging FIP- and RA9-WAR.) There are 31 pitchers who have accumulated a similar WAR total through a similar age. Of these, 17 have been inducted.
That said, it’s possible. His career, if it’s indeed over, seems borderline by traditional standards. However, he has a Cy Young and a perfect game on his resume and he was the face of a franchise for over a decade. Finally, writers are starting to recognize that WAR underrates modern starting pitchers due to historical workload differences. I think it’s unlikely this realization takes hold in time for him to get in on a BBWAA ballot, but a committee may feel differently later on.
Then there’s the crop of recently retired or soon-to-retired catchers. Many around the game view Joe Mauer and Buster Posey as certain inductees due to their WAR totals, positive reputations, associations with a single franchise, MVP awards, and postseason success (in Posey’s case). Do you consider Brian McCann and Russell Martin, both with similar WAR totals but fewer accolades, Hall of Famers? The model sees both as roughly a 50/50 shot to get in. Remember those committees!
What does the model get wrong? I think it undersells the chances of David Ortiz, Ichiro Suzuki, and Yadier Molina. I see a pattern here: these are classic “more than their stats” guys who have strong positive reputations that will increase their chances of induction. I also think that writers will want a palate cleanser, a positive story, after debating scandal-ridden candidates for so long. As these more writer-friendly guys get in, I’ll test this theory by adding a predictor to the algorithm.
There’s a ton more I could cover here and a lot I could do to improve future iterations, but I’m already pushing 2,000 words. No model can ever fully capture the ins and outs of Hall of Fame voting, but I think this one takes a decent shot. I’d love to know your thoughts on the predictions it makes.
Ryan enjoys characterizing that elusive line between luck and skill in baseball. For more, subscribe to his articles and follow him on Twitter.
Thanks for putting this together, really interesting work. A small flurry of clarifying questions I’m curious about:
1. “This causes some weirdness, like making Cody Bellinger a first baseman because he has more innings there than at any outfield position, but it works.”
Could you elaborate on how you qualify “it works?” Is it more accurate by doing this rather than grouping the HOF outfielders as one category?
2. How did the confusion matrix look without using SMOTE resampling? Personally, I’ve always just found that it lowers overall accuracy by raising both the True and False Positive rates.
3. A bit in the weeds, but what were the hyperparameters you settled on? Specifically curious about tree depth and number of trees.
4. “I didn’t predict anyone who is on the 2022 ballot because I used their data to train the model.” I guess you input them as not-HOF? You might have some incorrect negatives there, right?
Other unsolicited thoughts:
– I’d be curious to see a plot of p(HOF) vs WAR for each decade for players without scandals. It’d be a good way to quantify “This variable captures the fact that Hall of Fame standards and voting patterns have changed drastically over time.”
– One feature that might be interesting to add is postseason credentials (maybe a count variable for times in each round, then one for winning the WS).
– I think the three undersells you mention all have different reasons, you might be able to correct somewhat for them:
1. iirc Ortiz was on the anonymous ped list, but never suspended, leading to some ambiguity. Could use “ped suspension” as your scandal variable.
2. Suzuki’s late MLB debut is going to cause problems with cumulative war and age. If you swapped age to “years from debut,” it might be a bit better on him. (Though you’ll also run into the problem of a shorter career length, so you might need to also factor in “age at debut” or something, a lot of options there)
3. Two thoughts on Molina. One – catcher framing is only recently understood and probably tough to factor into the model. Two – there’s probably a bit of a bump for longevity with a single team, you could consider adding a predictor for “longest stint with a team.”
Thanks Tyler and I love all the thoughts and suggestions! My to-do list is overflowing now 🙂
1. So, fair question and I don’t have a great answer. I didn’t do any empirical tests of treating OF’s together vs. splitting them out into positions. I just wanted to be as accurate as possible when handling players’ positions, on the hypothesis that voters consider this as a factor.
Thinking about it more, Bellinger is such an obvious “Uh, he’s NOT a first baseman” that I could have simply hard-categorized him at CF. I may see if there are other patterns like him and if so, adjust my positional-selection logic accordingly. Maybe weight position by where they’ve spent the majority of their time in the last 2-3 years?
2. I looked at this at some point during the modeling process but didn’t keep track of the data along the way. I’ll look into this for a future iteration and see if removing SMOTE yields any improvements. Perhaps the stratified sampling / folding will be enough.
3. 150 trees at a depth of 17. Going higher on the tree count didn’t have any effect, and honestly I probably could’ve gone lower as well. Other params:
eta = 0.0894695203381641, gamma = 6.97298688837654e-09, colsample_bytree = 1, colsample_bynode = 1, min_child_weight = 33, subsample = 0.913027453709859
4. That’s right, I coded players on the 2022 ballot as “not elected”. Can you clarify what you mean by “incorrect negatives” ?
In any future articles I think readers will be interested in the chances of players currently on the ballot, so I’ll likely remove them from the training data, and include their predictions, for this reason alone.
Thanks for all the other suggestions. In particular I think there’s a lot worth exploring on the ‘value accrued with a single team’ perspective that you mention for Molina. This would affect Ortiz as well. Coincidentally enough Bill James published research on this recently: https://www.billjamesonline.com/vagabonds_and_homebodies/.
And I will play around with postseason, career length, etc variables. Right now, my working hypothesis is that there is a “strong positive narrative” factor, an anti-PED scandal variable if you will, that can explain Suzuki, Ortiz, and Molina among others. (e.g. I think it highly possible that David Wright will get elected, not by the writers but by a committee).
Once again thank you for taking the time to ask so many thought provoking questions and provide so many interesting suggestions. Always room for improvement! I may DM you on Twitter for a further convo …
So would you classify Stan Musial at 1B or LF?
I have him classified as LF, because that is where he’s classified on the HOF website: https://baseballhall.org/discover-more/stories/hall-of-famer-facts/hall-of-famers-by-position
Cool to see SMOTE actually work well for a problem! One trick I do for trees is set the n_trees to a high value, then use early stopping to catch when it stops improving.
What I meant about 2022 is that the ballots are still not counted, inductees aren’t in. It looks possible nobody would get in, but Ortiz, for example, has a shot. If he gets in, but you have him set as “not elected,” that might be a problem. Unless I’m misunderstanding the original sentence.
Great tip about early stopping. I forgot about that and scale_pos_weight as well. I’m sure I can get some improvements by using those.
Maybe I misunderstood, not you 🙂 I don’t have Ortiz set as ‘not elected’. Since he hasn’t been voted on yet (or, we don’t have the results yet), he’s not in the training data. Same with A-Rod and other first-timers.
If Ortiz gets in, I’ll update the training data to encode him as ‘elected’ and re-run everything; there’ll be a new data point for the model to consider.
I do have all second+ timers like Bonds, Vizquel, Schilling, etc. coded to ‘not elected’ since they have been voted on / considered but not elected. If any make it in, I’ll update the data and re-run.
So I just ran a quick test without SMOTE and the metrics are slightly worse: AUPRC 0.84, balanced accuracy 0.80, F1 0.72. Seems like having the algorithm in there helps.
Good job, Ryan. Now I’ll be sure to save this article and reread it in 2047 to check how accurate your model is.
I’ll be waiting with my Wander Franco jersey on!!
This is great! Interesting for sure, especially on Juan Soto (which I agree with).
Since there is a scandal component to the system, I’m curious why Correa grades out so much higher than Altuve. People have gone out of their way to support Altuve while Correa admits he cheated, and Altuve’s black ink is normally a major selling point in a HOF candidate.
Thanks! Yeah Soto was one of the motivators for this project. I’m just astounded at how good he is at such a young age and wanted to see where he might end up.
Good question on Correa vs. Altuve. Tentatively I’ll say that although Altuve has a higher WAR/year page than Correa, he is 5 years older and so perhaps the model sees him petering out sooner. It could also be that voters are harsher on 2B than they are on SS. I agree they’re perceived as having different levels of culpability in the scandal, but until voting starts on them, we won’t know for sure.
This is great work! Couple of thoughts on low hanging fruit to potentially improve the accuracy…
Rather than trying to predict rest-of-career performance in the model directly, relying on ZiPS would probably be more accurate. ZiPS is technically playing a similar trick but with a much more specialized and robust model, giving you better numbers to base on. This should also simplify the training.
It would also probably be worthwhile to break WAR up into its constituent components, or at least *include* those constituent components as features. This will quickly run into era adjustment issues, so you might want to normalize to league average year-over-year or something similar, but it’s almost certainly going to give you a more accurate fit, particularly since prior eras aligned voting patterns with more traditional stats than modern eras, meaning that WAR is almost certainly a better predictor now than it was then.
Speaking of stats, I would also play the JAWS trick and split out peak from overall career. (or rather, have them both) Among other things, this will probably improve Pujols’ prediction markedly.
Additionally and unrelated to the above, adding WPA and splitting it by regular season, postseason, and world series (then normalizing to a rate stat to avoid shifting everyone onto Jeter’s scale) would almost certainly help the predictiveness. “Big moments in big games” counts for a lot, particularly in historical voting trends. See also Jack Morris.
Finally, adding a few more “subjective” features to try to capture things like “team leadership” and such. This will be hard to populate automatically though, so it might not be worth the effort, but this would almost certainly do a better job of grading Ortiz and Molina, while only enhancing the fit on players like Jeter and maybe even Bonds (in the other direction).
Thanks for the detailed feedback and suggestions! I’ll test out several of these for sure. I love the idea of splitting WAR into its constituent components as well as peak and career scores. Great avenues for research.
I’ve already captured some of the subjective features using Bill James’ recent research here: https://www.billjamesonline.com/vagabonds_and_homebodies/ and not only are the model’s performance metrics drastically improved, it gets Molina and Ichiro over the line to induction. Jack Morris is a great example of a “big moment” guy along the lines of Ortiz. I’ll toy around with how to do that. Thinking of guys like Bill Mazeroski will fit that bill as well. I also think of guys like Jim Rice and Andre Dawson who may be are borderline stats-wise but had strong positive narratives that helped their candidacy.
LOL @ including Lars Nootbaar of all players in your tables!
Don’t sleep on the Noot!
Nolan Arenado is a head scratcher for sure. 9 GG’s, 5 Platinum gloves , 300th HR next season. He will meet the minimum requirement for the Hall next season and still have 6-7 more years left to add on !
McCann over Mauer is odd. Mauer will be a 1st ballot guy most likely. 2nd year at worst.
Thank you so much for this feedback. I incorporated MVP vote totals, time spent with a single franchise, and ASG’s and the model’s overall metrics improved drastically. And in this new and improved version, Nolan comes out on top at 3B. See it here: https://www.facebook.com/groups/effectivelywild/permalink/4849433875176759/
Apologies, maybe I missed a few things.
1) What’s with the three minor league players (Marcano, Pozo, Marchan) that all came from Venezuela?
2) Didn’t David Ortiz have some PEDs controversy as well?
I’m not sure it has anything to do with Venezuela. When you get to the bottom of a position barrel, the probabilities are all the same so what you’re seeing here is likely random selection of players there.
I did give Ortiz a “PED scandal” tag. Now that he was elected today, I’ll have to re run the model and see if I need to make any tweaks to it to account for this.
Time to update the model which gave Ortiz essentially zero chance of election.