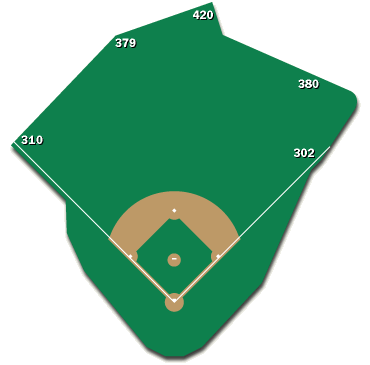
Complete Outfield Dimensions
I’ve been consistently dismayed at how metrics such as park factors could be calculated when it seems as if the fundamental data for calculating such metrics, the actual size and dimensions of MLB parks, is unknown.
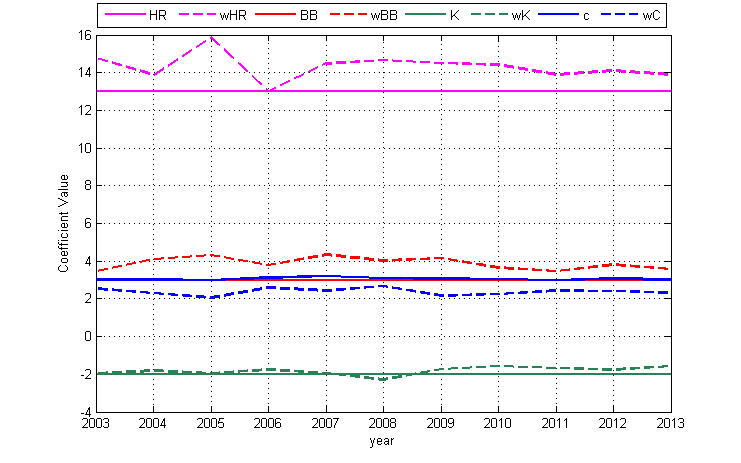
Any diagram or database of park dimensions I’ve found usually has LF, CF, and RF distances measured along with distances from home plate to the power alleys. A typical diagram is the following one of Fenway Park where five “important” distances have been marked.
The locations of these markings, particularly the power alleys, is extremely inconsistent across the different ballparks. In some parks the power alleys are measured at LCF and RCF (22.5° from each foul line), in other parks it’s where there is a corner in the outfield fence, and in other parks it’s just somewhere. In the Fenway image it’s impossible to tell where exactly any of those markings are and what any of the distances are between them. In any case, these five data points, plus any other distance markings, are not enough to define the shape and size of a ballpark.
We should be able to point in any direction in a ballpark and know the exact distance to the fence. Guessing by examining the proximity to the closest marked spot is insufficient for any real analysis. In order to understand the properties of a ballpark, to, for example, determine the ideal defensive positioning of the outfielders, we need to be able to mathematically define the boundaries, i.e. the location of the outfield fence.
These mathematical formulas defining the outfield fences are exactly what this article presents. If you look to the bottom of this article you’ll see the 30 equations that define the major league outfield fence distances from home plate. The equations are given in polar coordinates in terms of the angle θ from the right field foul line (RF=0°, LF=90°). The resulting distance, r, is given in feet.
The equations are all piecewise functions, with breaks between the sub-functions whenever the outfield wall changes direction. The sub-functions are given by linear functions or ellipses (all mapped to polar coordinates) where appropriate. Some ballparks are more complicated than others and that’s generally reflected in the number of required sub-functions. Some of the functions may seem intimidating, however, I would intend that any analysis with these functions would be done by computer, which makes the number of sub-functions in each piecewise definition generally irrelevant once the equations have been coded.
These equations were determined by examining the diagrams at ESPN Home Run Tracker, as well as park dimension data from Wikipedia, Clem’s Baseball, MLB team pages, and any other park diagrams I could find. These sources were not always in agreement and I used my best judgment when these situations arose, however I would guess that the standard error of the fence distance for any angle for any park is only a couple feet. There are also often many more precision digits that appear in the equations than necessary. This is for two reasons. The first reason is that it helps avoid discontinuities when transitioning between the functions and the second reason is that sometimes I just wrote down a lot of digits.
As a simple exercise of what can be done with this type of data, I’ve calculated the areas of the outfields of all the different MLB parks, as well as the respective sizes of left, center, and right field. The results are shown in Table 1 (sortable by clicking any of the header items). As an arbitrary start point, I assumed the outfield started 150 feet away from home plate and that each field spans 30°. Many of these results match our intuition (Yankee Stadium RF is tiny, Comerica Park CF is huge), but we now have numbers assigned to that intuition that can be analyzed.
| City | Team | Stadium | OF | LF | CF | RF |
|---|---|---|---|---|---|---|
| Arizona | Diamondbacks | Chase Field | 94.1 | 28.7 | 36.2 | 29.2 |
| Atlanta | Braves | Turner Field | 94.1 | 29.2 | 35.3 | 29.6 |
| Baltimore | Orioles | Oriole Park at Camden Yards | 87.8 | 27.1 | 34.4 | 26.3 |
| Boston | Red Sox | Fenway Park | 83.5 | 21.1 | 32.8 | 29.6 |
| Chicago | Cubs | Wrigley Field | 89.7 | 26.8 | 34.1 | 28.8 |
| Chicago | White Sox | U.S. Cellular Field | 87.8 | 26.5 | 34.2 | 27.2 |
| Cincinnati | Reds | Great American Ball Park | 87.1 | 26.7 | 34.5 | 26.0 |
| Cleveland | Indians | Progressive Field | 85.6 | 25.8 | 33.2 | 26.6 |
| Colorado | Rockies | Coors Field | 97.3 | 30.2 | 38.3 | 28.8 |
| Detroit | Tigers | Comerica Park | 95.8 | 28.5 | 39.9 | 27.4 |
| Houston | Astros | Minute Maid Park | 88.6 | 23.2 | 38.8 | 26.6 |
| Kansas City | Royals | Kauffman Stadium | 97.9 | 30.4 | 36.9 | 30.5 |
| Los Angeles | Angels | Angel Stadium | 89.2 | 29.0 | 32.7 | 27.5 |
| Los Angeles | Dodgers | Dodger Stadium | 91.1 | 28.8 | 33.8 | 28.5 |
| Miami | Marlins | Marlins Park | 93.4 | 28.3 | 36.9 | 28.3 |
| Milwaukee | Brewers | Miller Park | 91.1 | 28.9 | 34.6 | 27.6 |
| Minnesota | Twins | Target Field | 90.4 | 28.0 | 35.8 | 26.6 |
| New York | Mets | Citi Field | 91.5 | 27.1 | 36.0 | 28.4 |
| New York | Yankees | Yankee Stadium | 87.6 | 27.7 | 35.6 | 24.2 |
| Oakland | Athletics | O.co Coliseum | 88.4 | 27.5 | 33.4 | 27.5 |
| Philadelphia | Phillies | Citizens Bank Park | 86.2 | 25.7 | 34.9 | 25.5 |
| Pittsburgh | Pirates | PNC Park | 90.2 | 29.8 | 33.9 | 26.5 |
| San Diego | Padres | PETCO Park | 90.8 | 27.9 | 35.0 | 27.8 |
| San Francisco | Giants | AT&T Park | 92.2 | 27.3 | 36.2 | 28.7 |
| Seattle | Mariners | Safeco Field | 87.8 | 27.2 | 34.2 | 26.4 |
| St. Louis | Cardinals | Busch Stadium | 91.1 | 28.6 | 34.1 | 28.4 |
| Tampa Bay | Rays | Tropicana Field | 89.6 | 27.4 | 36.5 | 25.7 |
| Texas | Rangers | Globe Life Park in Arlington | 92.7 | 28.9 | 36.1 | 27.7 |
| Toronto | Blue Jays | Rogers Centre | 91.8 | 27.9 | 35.9 | 27.9 |
| Washington | Nationals | Nationals Park | 88.8 | 28.2 | 32.8 | 27.8 |
The previous definition of the different fields could be modified or determined based on the intended purpose. For example, for determining the outfield positioning, the relative speed of each fielder would determine the area for which each fielder is responsible. With these equations, those values can be exactly calculated. Also, just because two fields have the same area, does not mean they are of equal difficulty to defend. The shape of the fence determines how accessible the different parts of the area are. Again though, with these equations these shapes and values can be determined.
These equations are limited though in that they only define the outfield in fair play. For further research and to more completely account for different stadiums, the distances from the plate to the fence for all 360° of rotation should be known. Foul territory is a much greater consideration in some parks than others.
And now, the equations.
Arizona Diamondbacks – Chase Field

Atlanta Braves – Turner Field
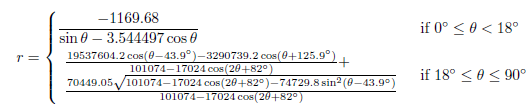
Baltimore Orioles – Oriole Park at Camden Yards
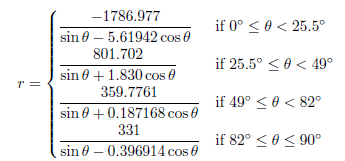
Boston Red Sox – Fenway Park

Chicago Cubs – Wrigley Field

Chicago White Sox – U.S. Cellular Field

Cincinnati Reds – Great American Ball Park

Cleveland Indians – Progressive Field
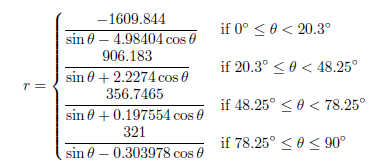
Colorado Rockies – Coors Field
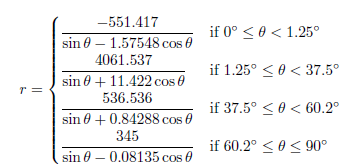
Detroit Tigers – Comerica Park
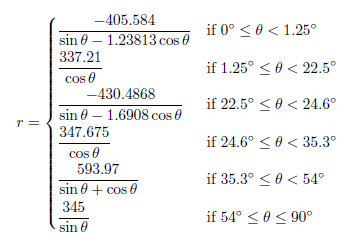
Houston Astros – Minute Maid Park

Kansas City Royals – Kauffman Stadium

Los Angeles Angels – Angel Stadium

Los Angeles Dodgers – Dodger Stadium

Miami Marlins – Marlins Park

Milwaukee Brewers – Miller Park

Minnesota Twins – Target Field

New York Mets – Citi Field

New York Yankees – Yankee Stadium

Oakland Athletics – O.co Coliseum

Philadelphia Phillies – Citizens Bank Park

Pittsburgh Pirates – PNC Park

San Diego Padres – PETCO Park

San Francisco Giants – AT&T Park
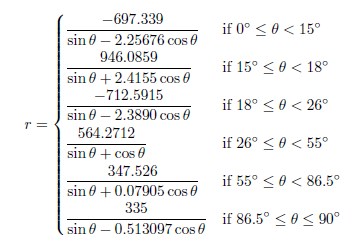
Seattle Mariners – Safeco Field

St. Louis Cardinals – Busch Stadium

Tampa Bay Rays – Tropicana Field

Texas Rangers – Globe Life Park in Arlington

Toronto Blue Jays – Rogers Centre
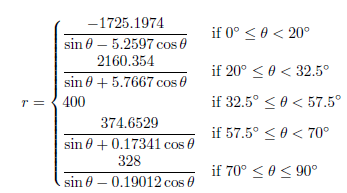
Washington Nationals – Nationals Park