Why I Don’t Use FIP
Over the last decade, Fielding Independent Pitching (FIP) has become one of the main tools to evaluate pitchers. The theory behind FIP and similar Defensive Independent Pitching metrics is that ERA is subject to luck and fielder performance on balls in play and is therefore a poor tool to evaluate pitching performance. Since pitchers have little to no control over where batted balls are hit, we should instead look only to the batting outcomes that a pitcher can directly control and which no other fielder affects. In the case of FIP, those outcomes are home runs, strikeouts, walks, and hit batters.
However there are many serious issues with FIP that collectively make me question its usage and value. These issues include the theory behind the need for such a statistic, the actual parameters of the formula’s construction, and the mathematical derivation of the coefficients. Let’s address these issues individually.
Control over Balls in Play
A common statement when discussing FIP or BABIP is that pitchers have little to no control over the result of a ball once it is hit into play. A pitcher’s main skill is found in directly controllable outcomes where no fielder can affect the play, such as home runs, strikeouts, and walks (and HBP). In trying to estimate a pitcher’s baseline ERA, which is the objective of FIP, the approximately 70% of balls that are put into play can be ignored and we can focus only on the previously mentioned outcomes where no fielder touches the ball.
The concept of control is a little fuzzy though and something I believe has been misappropriated. It is definitely true that the pitcher does not have 100% absolute control over where a batted ball is hit. There is no pitch that anyone can throw that can guarantee a ball is hit exactly to a particular spot. However in the same vein, the batter doesn’t have 100% absolute control either. If you were to place a dot somewhere on the field, no batter is good enough to hit that spot every time, even if hitting off a tee.
However this lack of complete control should not in any way imply that the batter or pitcher doesn’t have any control at all over where the ball is hit. Batters hit the ball to places on the field with a certain probability distribution depending on what they are aiming for. Better batters have a tighter distribution with a more narrow range of possibilities and can more accurately hit their target. For example consider a right-handed batter attempting to hit a line drive into left field on an 80 mph fastball down the heart of the plate. A good hitter might hit that line drive hard enough for a double 30% of the time, for a single 30% of the time, directly at the left fielder 10% of the time, and accidentally hit a ground ball 20% of the time. Conversely, a worse batter who has less control over his swing may hit a double 10% of the time, a single 10% of the time, directly at the left fielder 15% of the time, an accidental ground ball 25% of the time, and in this case not even get his swing around the ball fast enough and instead hits the ball weakly towards the second baseman 40% of the time.
Where the pitcher fits into the entire scheme is in his ability to command the ball to specific locations, with appropriate velocity and spin, as to try to sway the batter’s hit distribution to outcomes where an out is most likely. Consider the good hitter previously mentioned. He accomplished his goal fairly successfully on the meatball-type pitch. What if the same good batter was still trying to hit that line drive to left field, but the pitch instead was a 90 mph slider on the lower outside corner? On such a pitch the good batter’s hit distribution may start to resemble the bad hitter’s hit distribution more closely. This is a slightly contrived and extreme example, but it also encompasses the entire theory of pitching. Pitchers are not trying to just strike out every batter, but instead pitch into situations and to locations where the most likely outcome for a batter is an out.
By this reasoning the pitcher has a lot of control over where and how a batted ball is hit. This does not mean that even on the tougher pitch that the batter can’t still pull a hard double, or even that the weak ground ball to the second baseman won’t find a hole into right field, these are all still possibilities. However by throwing good pitches the pitcher is able to control a shift in the batter’s hit probability distribution. Similarly, better batters are able to make adjustments so that their objective changes according to the pitch. On the slider, the batter may adjust to try to go opposite field. However a good pitch would still make the opposite field attempt difficult.
This is all to say that better pitchers have more control over how balls are hit into play. They are able to command more pitches to locations where the batter is more likely to hit into outs than if the pitch was thrown to a different location. Worse pitchers don’t have such command or control to hit those locations and balls put into play are decided more by the whims of the batter. FIP takes this control argument too far too the extreme. There is a spectrum of possibilities between absolute control over where a ball is hit and no control over where a ball is hit that involves inducing changes in the probability distribution of where a ball is hit, which is how the game of baseball is actually played. As a simple example, we see that some pitchers are consistently able to induce ground balls more frequently than others. Since about 70% of all plate appearances result in balls being put into play, it is important to actually consider this spectrum of control instead of just assuming that the game is played only at one extreme.
Formula Construction
Let’s pause though and ignore my previous argument that a pitcher can control how balls are hit and we’ll instead assume that all the fielding independence theories are true and we can predict a pitcher’s performance using only the statistics in the FIP formula. This introduces an immediate contradiction since none of the statistics used in the FIP formula (except HBP, which has the smallest contribution and is a prime example of lack of control) are in fact fielder independent. The FIP formula is not actually accounting for its intended purpose.
The issue of innings pitched in the denominator has been addressed before. Fielders are responsible for collecting outs on balls in play which therefore determines how many innings a pitcher has pitched. However all three of the statistics in the numerator are also affected by the fielding abilities of position players, especially in relation to ballpark dimensions. Catchers’ pitch framing abilities have been shown recently to heavily affect strike and ball calls and could be worth multiple wins per season. Albeit rare events, better outfielders are able to scale the outfield fences and turn potential home runs into highlight reel catches.
More commonly though, better catchers and corner infielders and outfielders can turn potential foul balls into outs. When foul balls are turned into caught pop-ups or flyballs, the at bat ends, thus ending any opportunity for a walk or a strikeout which may have been available to a pitcher with worse fielders behind him. This is particularly harmful to a pitcher’s strikeout total. Whereas a ball landing foul only gives an additional opportunity for a batter to draw a walk, it also moves the batter one strike closer (when there are less than two strikes) to striking out.
Similarly, instead of analyzing the effects of the fielders, we can look at the size of foul territory. Larger foul territory gives more chances for fielders to make an out since the ball remains over the field of play longer instead of going into the stands. Statistics like xFIP normalize for the size of the park by regressing the amount of flyballs given up to the league average HR/FB rate, however there is no park factor normalization for the strikeout and walk components of FIP.
We can see the impact immediately by examining the Athletics and Padres, two teams whose home parks have an extremely large foul territory. By considering only the home statistics for pitchers who threw over 50 IP in each of the last five seasons, the Athletics pitchers collectively had a 3.25 ERA, 3.74 FIP, and 4.05 xFIP, while the Padres pitchers collectively had a 3.38 ERA, 3.84 FIP, and 3.86 xFIP. In both cases FIP and xFIP both drastically exceeded ERA. Also, of the 46 pitchers who met these conditions, only 9 pitchers had an ERA greater than their FIP and only 7 had an ERA greater than their xFIP, with 6 of those pitchers overlapping. This isn’t a coincidence. Although caught foul balls steal opportunities away from every type of batting outcome, it is more heavily biased to strikeouts since foul balls increase the strike count.
Mathematics
The mathematics of the FIP formula may be my biggest problem with FIP, mostly because it’s the easiest to fix and hasn’t been. I’ve seen various reasons for using the (13, 3, -2) coefficients in derivations of the FIP formula. Ratios of linear weights, baserun values, or linear regression coefficients are the most common explanations. However none of these address why the final coefficient values are integers, or why they should remain constant from year to year.
There is absolutely no reason why the coefficients should be integers. Simplicity is a convenient excuse, but it’s highly unnecessary. No one is sitting around calculating FIP values by hand, it’s all done by computers which don’t require such simplicity. By changing the coefficients from their actual values to these integers, error and bias is unnecessarily introduced into the final results. Adjusting the additive coefficient to make league ERA equal league FIP does not solve this problem.
The baseball climate also changes yearly. New parks are built and the talent pool changes. This changes the value of baseball outcomes with respect to one another. It’s why wOBA coefficients are recalculated annually. However for some reason FIP coefficients remain constant. The additive constant helps in equating the means of ERA and FIP but there is still error since the ratios of HR, BB, and K should also change each year (or at least over multi-year periods).
I’ve calculated a similar version of FIP, denoted wFIP, for the 2003-2013 seasons using weighted regression on HR, (HBP+BB), K, all divided by IP as they relate to ERA. If we treat each inning pitched as an additional sample, then the variance of the FIP calculation for a pitcher is proportional to the reciprocal of the amount of innings pitched. Weighted regression typically uses the reciprocal of the variance as weights. Therefore in determining FIP coefficients we can use each pitcher’s IP as his respective weight in the regression analysis. The coefficients for the weighted regression compared to their FIP counterparts are shown in the following graph.
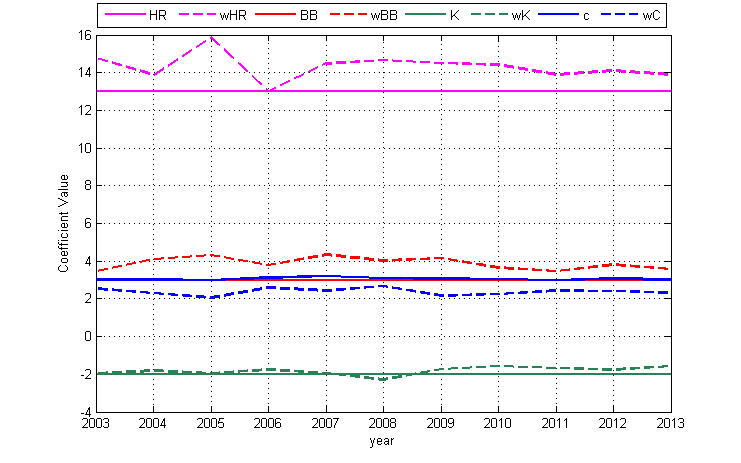
Ignoring the additive constant, since 2003 each of the three stat coefficients have varied by at least 22% from the FIP coefficient values and are all biased above the FIP integer value almost every year. In 2013 this leads to a weighted absolute average difference of 0.09 per pitcher between the wFIP and FIP values, which is about a 2.3% difference on average. However there are more extreme cases.
Consider Aroldis Chapman, who had a 2.54 ERA and 2.47 FIP in 2013. On first glance this seems to indicate a pitcher whose ERA was in line with his peripheral statistics and if anything was very slightly unlucky. However his wFIP came to 2.96. If we saw this as his FIP value we might be more inclined to believe that he was lucky and his ERA is bound to increase. This difference in opinion would come purely from use of a better regression model, without at all changing the theory behind its formulation. That is a poor reason to swing the future outlook on a player.
However even with current FIP values, no one would draw the conclusions I did in the previous paragraph that quickly. Upon seeing the difference in FIP (or wFIP) and ERA values, one would look to additional stats such as BABIP, HR/FB rate, or strand rate to determine the cause of the difference and what may transpire in the future. This in fact may be the ultimate problem with FIP. On its own it doesn’t give us any information. Even with the most extreme differentials we always have to look to other statistics to draw any conclusions. So why don’t we make things easier and just look at those other statistics to begin with instead of trying to draw conclusions from a flawed stat with incorrect parameters?
You should feel honoured if Tom Tango rips this on his blog.
His usual response to this kind of complaint is that FIP isn’t meant to predict ERA. FIP is a stat of its own, to be used like K/BB, GB%, whatever, and supplemented with additional data. Sure, it’s scaled to ERA, but that part is just to make it easy to understand on it’s own without comparing multiple players. Nobody complains about wOBA not being a perfect estimator for OBA. They are completely different stats. (wOBA is another Tango creation).
Tango does say that FIP is only a component of a total pitching stat, in his own words
ERA = FIP + FDP + Fielding + luck
But by doing a regression or using linear weights from other run-based metrics to determine FIP, whether intentionally or not, it does become an estimator of ERA with all those other terms captured in the variance.
I do have a problem with saying that FIP is scaled to ERA though. The way it is calculated, saying that they are scaled to each other is by making ERA=FIP+c. But why not equate their averages by doing ERA=k*FIP similar to wOBA. These would both equate the averages, but neither of them place the two metrics on the same scale.
Thanks Andrew, this article is fantastic and necessary to keep advancing the tools we use.
I can’t stress enough how important it is to understand the bias and limitations inherent in a tool before putting it to use, in this case making conclusions.
Like any comprehensive statistic, FIP has issues, and I’m sure even its strongest proponents are aware that it does. That being said, I like:
The Mathematics section…it provides simple, constructive changes that increase the accuracy and precision of FIP.
I don’t like:
The conclusion…I find FIP to be greatly useful. It gives me a baseline from which to evaluate players. The other factors help determine why or how they are over/underperforming that FIP.
Your argument is essentially, “just look at all the underlying factors first,” which is like saying “screw WAR, just look at UZR/150, ISO, BABIB, and K/BB%!” The whole point is to integrate multiple factors into a cohesive summary, which FIP does relatively well, as far as pitcher evaluation goes.
Thanks for writing, and keep questioning everything for the sake of improvement, not cynicism 🙂
“Like any comprehensive statistic, FIP has issues”
The problem with that statement is that FIP is not comprehensive. It intentionally ignores a large amount of information.
Great article Andrew. Hopefully it is at least the catalyst for some change in the way FIP is calculated.
Our of curiosity, what do you use to evaluate pitchers? SIERA?
It definitely depends on what type of evaluation I want to do, specifically whether it is evaluating past performance or trying to predict future performance.
SIERA has its faults but it is definitely more encompassing than some of the other metrics.
I am always a fan of looking at some of the base metrics that don’t involve estimators though, eg. HR/FB, BABIP on different types of hits plus the distribution of those types of hits compared to league average/career numbers/similar players/some combination. I find when looking for a reason to make a prediction on a player it is helpful to try and identify particular aspects of his game which may cause the effects.
You consider simplicity to be a poor excuse for keeping integer coefficients, but I find this is one of the best parts about FIP. I use baseball-reference to look up players and stats much more often than fangraphs and the integers make it a relative breeze to calculate in my head, only slightly harder than batting average would be. I realize most are probably not using it in this way, and I applaud your efforts to improve something you see as lacking, but FIP’s simplicity is part of the reason why I even use it.
The integers are only part of the mental math though. You also have to do a division by IP. If you can handle dividing by an inning total like 187 in your head and getting one or two decimals of precision for FIP, then you can probably also handle a decimal or two on the HR/BB/K coefficients when you do the multiplication.