Looking for a Breakout Performance
Every franchise is looking for that player who seems to come out of nowhere to be a major contributor in their lineup. Players like José Bautista, who went from 1.8 WAR in 2009 to 6.5 WAR in 2010, or Justin Turner, who jumped from 0.5 WAR in 2013 to 3.4 WAR in 2014. The cost for acquiring these players was affordable because they were no longer prospects and most of the league had written them off as potential everyday players.
If a team had the ability to identify which players are most likely to exceed industry expectations, they would have a significant advantage over their competition. That is why I decided to create a model that tries to identify potential breakout performers.
Methodology
The first thing I needed to do was to define what constitutes a breakout performance. I thought of several different definitions, but I decided to define a breakout performance as any player that exceeded their career high WAR in a single season by at least 2.0 WAR. So if a player had recorded a season of 0.0 WAR, they would need to have at least a 2.0 WAR season. If a player had recorded a season of 1.0 WAR, they would need to have at least a 3.0 WAR season and so on and so forth.
I chose 2.0 WAR because it seemed like a reasonable balance of making it a difficult threshold for a player to reach but also not limiting the number of positive cases. If there are not enough positive cases in a model, it can hurt the model’s performance. I also thought that 2.0 WAR is about what the average MLB player produces in a full season, so using that as a cutoff would be akin to a team gaining a league-average player for no cost.
Using a binary variable instead of a continuous variable to define a breakout performance means that I can use a logistic regression model to predict which players are the most likely to outperform their previous seasons. Now that I have determined which model to use, the next step is to determine what the data set will be.
Collecting the Data
To create a data set, I started with players that started their domestic professional baseball career in 2006 or later. I chose 2006 as a cutoff because it is the furthest back that minor league data is available on FanGraphs, and I only wanted to include players with their full minor league history.
I also decided to only include 2006 to 2019 MLB data. The shortened 2020 season would be difficult to include in a project of this nature, so I decided to only include full seasons in the data set, and this would still allow me to use 2021 data to check the validity of the model.
Next I limited the data set to include only players with 300 or more career major league plate appearances. I chose 300 because it is a reasonable number of plate appearances for evaluators to form an opinion on a player while still allowing for further growth and development at the major league level.
Allowing players with fewer than three hundred plate appearances would allow for more prospects in the analysis. However, the objective of this project is to find players that are most likely to outperform their previously observed production. Prospects do not have enough of a major league record to compare to, so it would be unwise to include them in the model.
Building the Model
After these restrictions, the data set consisted of 1,684 players. The next thing I needed to do was determine which variables to use in the model. I considered a variety of major league and minor league statistics, the prospect’s highest Baseball America prospect ranking, and personal details like height, weight, age, position, and birth country. After several implementations, the final model consisted of eight variables: season age, BMI, previous season WAR, season-high WAR, MLB ISO, MLB speed score, MiLB walk rate, and MiLB batting average. Below are the coefficients for each variable in the model.

Most of the variables have a positive value except for season-high WAR and age. This means that the older a player is and the higher their season-high WAR is, the lower their chances are of having a breakout performance. This may seem counterintuitive for season-high WAR. However, it makes sense that a player like Bryce Harper or Mike Trout would have more difficulty producing a 12-win season than someone like Turner needing to only produce a 2.5-win season in 2014. The higher your breakout threshold is, the more things like injuries can derail your chances of posting an extremely high WAR total.
The other thing that caught my attention is that BMI has a positive coefficient value instead of a negative one. Sometimes a high BMI can be an indicator of poor health, but BMI is an extremely crude measurement. It does not consider things like muscle mass or waist size, and many professional athletes are obese by this BMI measurement when they just have far more muscle mass than the general population. My theory is that many players in the model with a high BMI are extremely fit individuals with high muscle mass and this is what is causing a positive coefficient value. If I had access to more precise body measurements, I would certainly include it in the modeling process.
Testing the Model
With the model completed and the 2021 season officially in the books, I can now examine the accuracy of the model for this past season. There were 303 position players with over 300 career plate appearances in the data set and below is a confusion matrix showing how many of the model’s predictions were correct.
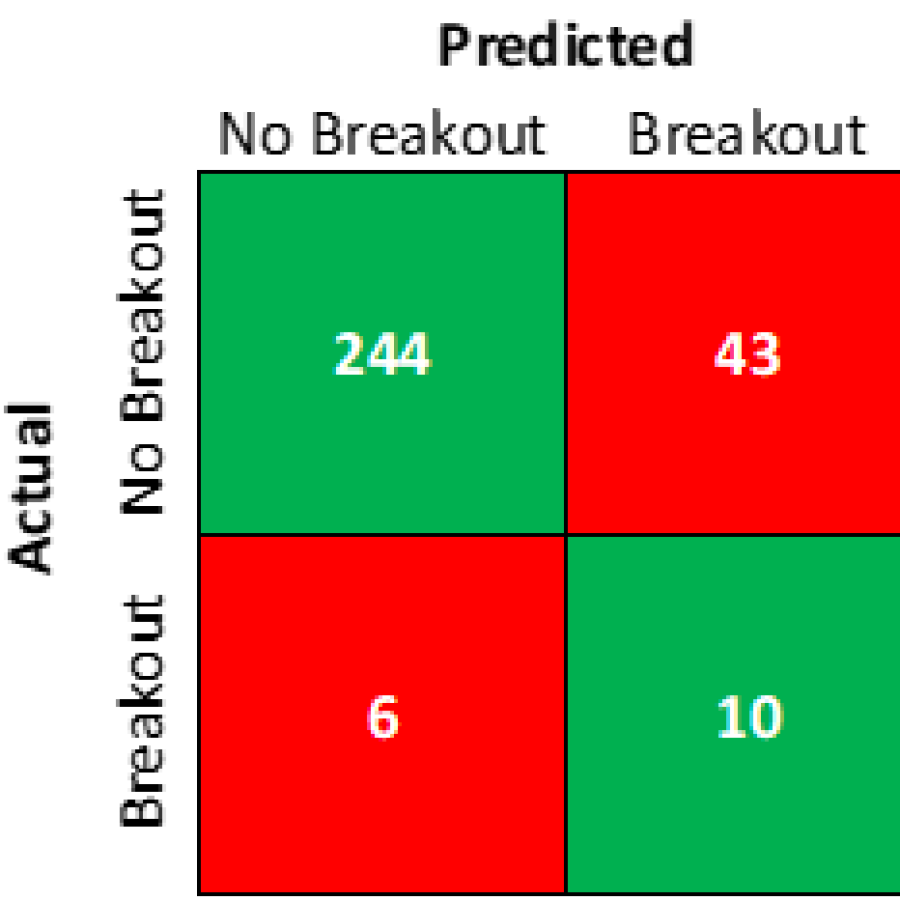
The model’s overall accuracy was 83.83% with 254 of the 303 total predictions being correct, with 244 of the 250 predicted non-breakouts being correct and 10 of the 53 predicted breakouts being correct. These results are consistent with the testing set I used to calibrate the model, so I am satisfied that the model is performing as expected.
The model is clearly better at distinguishing which players are not going to breakout versus finding players that will breakout. Since many breakout performances seem to come out of nowhere, it makes sense that breakouts would be more difficult to identify. This means that the model is better at eliminating a large amount of breakout candidates and finding potential breakout candidates, rather than accurately predicting breakout candidates.
For anyone who is curious, below is a list of the sixteen players that had a breakout season in 2021 with their 2021 WAR, their previous season-high WAR, and their predicted chance of a breakout performance.

There are some hits in here with Vladimir Guerrero Jr., Austin Riley, Kyle Tucker, and others easily reaching the 2-win improvement threshold, but there are also some misses like Shohei Ohtani, Bryan Reynolds, and Trea Turner.
I think Ohtani is the most egregious miss, but I would like to point out that he had no minor league data and a poor 2020 showing that severely brought down his breakout prediction. So the result looks bad, but I understand why the model missed on his 2021 breakout.
2022 Breakout Candidates
Since the model seems to be serviceable, the next step is to look for potential breakout performances in 2022. Below is a list of the 61 players that the model predicts will breakout along with the player’s most recent team, their 2022 season age, 2021 WAR, the WAR threshold for a breakout season, and the percent chance the model predicts for the player having a breakout season.
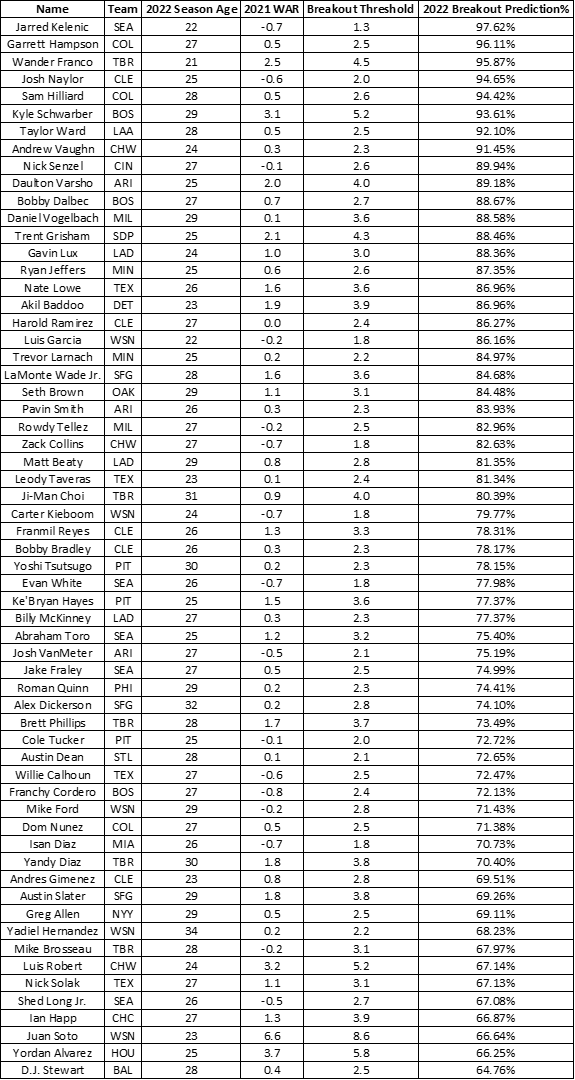
Before anyone starts buying Garrett Hampson and Sam Hilliard stock, please remember that the model is far more accurate at predicting which players will not breakout, so there are many players on this list that will not reach their breakout threshold. However, the chances of finding a breakout season from a player not on this list is going to be much lower.
It is my hope that this model will continue to identify future MLB contributors and I look forward to revisiting the subject when more data from Statcast is available. I believe that player measurements like exit velocity and launch angle could drastically improve model performance and I plan to incorporate them into the model in the future.
More of my work can be found at my website or on Twitter.
Who’s on your “won’t breakout” list? Perhaps another article 😉
I could post the list, but I prefer to look at the positive cases when it comes to players. They don’t need any more outsiders telling them they’re not going to be great, you know?
Except that it’s a good check when someone posts an article saying “so and so is a breakout candidate.” Nice work!
Thanks for the research! That’s great. I’m curious for the 2021 data who was a “Predicted Breakout” but did not in fact break out (especially with the Breakout Prediction % as well)
The formatting may be a bit off-putting, but here are the players that were predicted to breakout in 2021, but ultimately fell short:
+——————-+———-+——————–+—————————+
| Name | 2021 WAR | Breakout Threshold | 2021 Breakout Prediction% |
+——————-+———-+——————–+—————————+
| Garrett Hampson | 0.5 | 2.2 | 97.55% |
| Josh Naylor | -0.6 | 2.0 | 96.71% |
| Nick Senzel | -0.1 | 2.6 | 94.86% |
| Trent Grisham | 2.1 | 4.3 | 94.60% |
| Daniel Vogelbach | 0.1 | 3.6 | 90.73% |
| Rowdy Tellez | -0.2 | 2.5 | 90.42% |
| Harold Ramirez | 0.0 | 2.4 | 89.34% |
| Franchy Cordero | -0.8 | 2.4 | 88.21% |
| Matt Beaty | 0.8 | 2.6 | 87.39% |
| Dominic Smith | -0.5 | 3.8 | 87.37% |
| Alex Dickerson | 0.2 | 2.8 | 85.99% |
| Juan Soto | 6.6 | 6.9 | 85.14% |
| Richie Martin | -0.5 | 1.0 | 84.93% |
| Clint Frazier | -0.9 | 3.4 | 84.57% |
| Billy McKinney | 0.3 | 2.1 | 83.50% |
| Kyle Schwarber | 3.1 | 5.2 | 83.38% |
| Eloy Jimenez | 0.2 | 3.8 | 83.11% |
| Ryan McMahon | 2.5 | 2.7 | 83.08% |
| Nick Solak | 1.1 | 2.4 | 82.39% |
| Austin Slater | 1.8 | 3.2 | 82.00% |
| Jesse Winker | 3.2 | 3.4 | 81.98% |
| Ji-Man Choi | 0.9 | 4.0 | 81.75% |
| Josh VanMeter | -0.5 | 2.1 | 79.69% |
| Ian Happ | 1.3 | 3.9 | 79.52% |
| Austin Dean | 0.1 | 2.0 | 79.17% |
| Roman Quinn | 0.2 | 2.3 | 78.60% |
| Keston Hiura | -0.7 | 4.1 | 77.43% |
| Willie Calhoun | -0.6 | 2.5 | 76.62% |
| Yandy Diaz | 1.8 | 3.6 | 75.85% |
| D.J. Stewart | 0.4 | 2.5 | 74.48% |
| Brett Phillips | 1.7 | 3.1 | 73.94% |
| Tyler Wade | 0.9 | 2.3 | 73.25% |
| Tony Kemp | 2.7 | 2.9 | 72.19% |
| Greg Allen | 0.5 | 2.2 | 71.51% |
| Anthony Santander | 0.7 | 2.9 | 71.32% |
| Francisco Mejia | 1.4 | 2.6 | 70.19% |
| Ronald Guzman | -0.2 | 2.4 | 70.00% |
| Franmil Reyes | 1.3 | 3.2 | 69.95% |
| Lewis Brinson | -0.2 | 1.8 | 68.51% |
| Jake Bauers | -0.7 | 2.7 | 67.32% |
| Luke Voit | 0.4 | 4.0 | 66.76% |
| Rio Ruiz | -0.4 | 2.3 | 64.63% |
| J.P. Crawford | 3.1 | 3.3 | 64.27% |
+——————-+———-+——————–+—————————+
Thank you!
It’s a combo of playing time and improvement of skill(s). It’d be interesting to see which drove prediction% the most in each case.
Good article, but in cases like this with imbalanced data (there are far more non-breakouts than breakouts), simple accuracy doesn’t describe the model’s performance well. More here: https://machinelearningmastery.com/failure-of-accuracy-for-imbalanced-class-distributions/.
To get a sense of the problem, the data is so imbalanced (heavily skewed towards non-breakouts) that a simple ‘naive’ guess of “no-breakout” would be correct 82.5% of the time (250 actual non-breakouts / 303 total data points). A model that’s accurate 83.4% of the time is only a minuscule improvement over this naive guess, likely not worth the effort if someone were to use it instead of making a naive guess.
The model’s performance is probably better described using something like ‘balanced accuracy’ or F-score.
I only say this because I ran into a similar challenge predicting batted ball results. 3/4 of batted balls are outs — so any model you build has to be an improvement on that 75% accuracy rate of just guessing “out” for every result.
There are many resources besides what I linked for dealing with imbalanced data in classifiers, hopefully you find some useful.
You are absolutely correct that imbalanced data can cause significant model calibration issues and that accuracy alone is not the best measure of a model’s success.
That’s why for the model calibration I used SMOTE from the DMwR package to balance the data in my model and I also used ROC curves to evaluate the model’s effectiveness.
I just find that most people do not find model diagnostics fun to read, so I left them out of this article.